Bài viết này hướng dẫn các bạn retrain cascade model theo nhu cầu sử dụng. Thí dụ như muốn model nhẹ hơn để chương trình chạy nhanh và nhẹ hơn. Hoặc đôi lúc bỏ sót vật thể thì cần bổ sung thêm hình ảnh mới.
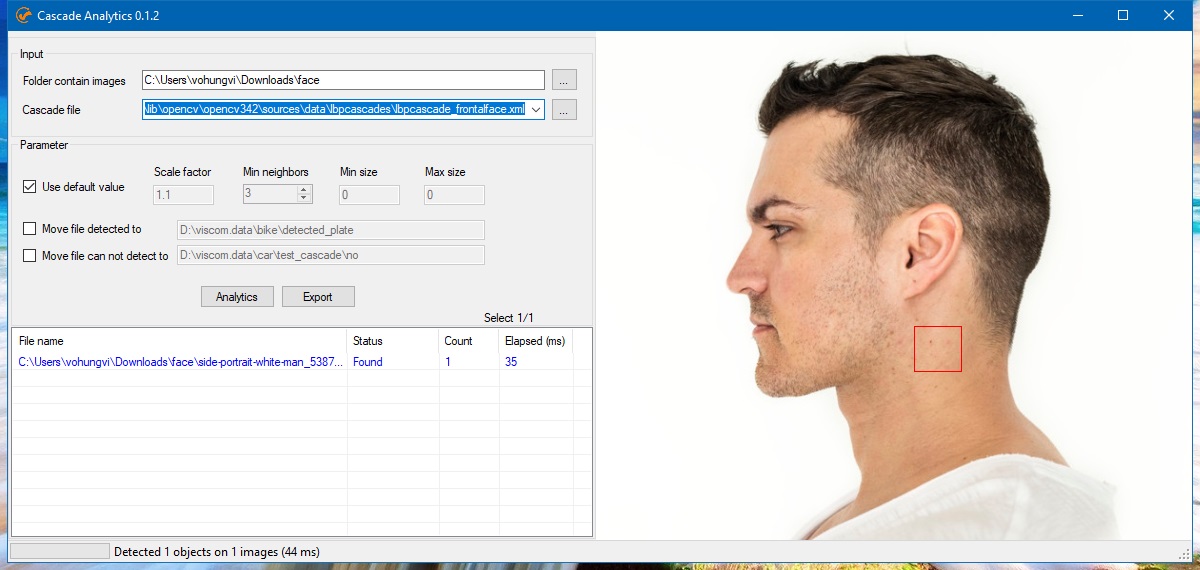
Dùng tool Cascade Analytics test file lbpcascade_frontalface.xml thì nhận nhầm 1 khuôn mặt (False Positive). Để chính xác hơn thì cần phải training lại, training nhiều lần đến khi đúng thì thôi.
Hoặc các trường hợp sử dụng đặc biệt khác mà bạn cần training lại theo mục đích sử dụng. Có thể là xe cộ, chó mèo,… bài viết này tập trung vào khuôn mặt cho dễ hình dung.
Đây là bài viết nâng cao trong seri nhận diện khuôn mặt. Để hiểu bài này các bạn cần đọc lý thuyết & làm ví dụ trong OpenCV cơ bản. Cần đọc và làm theo 3 bài viết sau để hiểu bài này:
1. Phát hiện vật thể – P1: lý thuyết
2. Phát hiện vật thể – P2: thực hành
3. Phát hiện vật thể – P3: kinh nghiệm & hỏi đáp
Lý thuyết
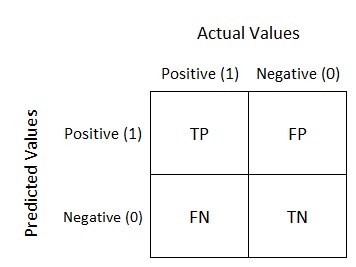
Trong confusion matrix thì độ chính xác (accuracy và precision) được tính bởi 4 ô: TP, FP, FN và TN. TP và TN là chính xác rồi, chúng ta cần giảm con số của FP và FN xuống. Download tài liệu về đánh giá độ chính xác ở cuối bài.
Trong hình đầu tiên của bài thì không có khuôn mặt mà lại báo là có, đó là FP (False Positive). Ta cần lấy hình này bỏ vào bộ ảnh Negative để máy học được rằng không có khuôn mặt trong ảnh vừa đưa.
Các vấn đề cần quan tâm khi retrain cascade model (cũng như các giải thuật khác) là:
– Thu thập thêm data: cần phải bao quát đủ các trường hợp sử dụng
– Tinh chỉnh tham số (tuning): để detect chính xác hơn
– Cuối cùng là lưu trữ: giữ lại bộ data để có thể sử dụng lại sau này
Thu thập thêm data
Kiếm data khuôn mặt có vài cách: download video hài từ youtube hoặc Google images. Với video thì tiến hành extract khuôn mặt của từng frame, với ảnh cũng thế. Crop lại rồi save vào folder positive

Khi extract ra sẽ có ảnh khuôn mặt không đúng, ảnh nào không đúng bỏ vào folder Negative. Nguyên tắc phân chia dữ liệu rất đơn giản: ảnh có khuôn mặt bỏ vào folder positive. Ảnh nào không có khuôn mặt bỏ vào negative
Trong quá trình phân loại thủ công, các bạn có thể loại bỏ các khuôn mặt nhìn nghiêng, nhòe,… Miễn sao dữ liệu giữ lại đúng với mong muốn của các bạn. Tuy nhiên khuôn mặt nhìn nghiêng cũng là khuôn mặt, do đó delete đi chứ đừng bỏ vào folder negative. Bỏ vào negative sẽ giảm độ chính xác rất nhiều.
Tinh chỉnh tham số
Khi training có nhiều tham số, trong đó các tham số quan trọng như:
-featureType: nên chọn LBP để tiết kiệm thời gian, độ chính xác cũng tương tự HAAR
-numPos: nên chuẩn bị 2000 ảnh postive trở lên, tốt nhất là từ 3000 – 4000 ảnh
-numNeg: tầm 3000 ảnh là phù hợp
-w -h: nên giới hạn trong khoảng 30 – 40, và w càng gần bằng h càng tốt, tốt nhất là w=h
-minHitRate: nên để 0.999999 để tăng độ chính xác (default là 0.995)
-maxFalseAlarmRate: nên để default là 0.5, giảm xuống 0.4 tốn thời gian kinh khủng
Với những tham số recommend ở trên, mình training lại với máy tính của mình tầm 4 tiếng. Download file cascade mình đã training lại ở cuối bài.
Lưu trữ data
Việc lưu trữ rất cần thiết cho làm việc lâu dài, mình đề nghị các bạn sử dụng SVN để lưu trữ. Phương pháp là tạo 1 repository ở trong máy để có thể xem lại lịch sử thu thập ảnh.
Các command để training cũng save lại file text để commit lên SVN. Mỗi lần chúng ta training lại đều commit để xem lại quá trình thực hiện. Như vậy mới thống kê được với những sự thay đổi về số lượng ảnh, tham số thì độ chính xác thay đổi ra sao.
Download
Bộ ảnh dưới đây mình extract ra từ các video hài trên youtube. Có kèm câu lệnh trong file _command.txt, các bạn sửa tham số cho phù hợp để training.
Face_frontal.zip (60MB)
Model face cascade đã training lại lbpcascade_face_viscom.xml
Tài liệu đánh giá độ chính xác training: cac_phuong_phap_danh_gia_he_thong_phan_lop.pdf