1. Giới thiệu về OCR
Hệ thống nhận dạng chữ viết (Optical Character Recognition – OCR) đã được sử dụng rộng rãi trong thực tế như đọc hoá đơn, các loại giấy tờ cá nhân. Tuy nhiên OCR vẫn là một vấn đề đầy thách thức về cả độ chính xác và tốc độ tính toán. Các công cụ và các thuật toán trích xuất ngày càng được phát triển và làm việc hiệu quả trong việc nhận dạng và phân tích cấu trúc.
2. Giới thiệu PaddleOCR
PaddleOCR là một framework mã nguồn mở được phát triển bởi Baidu PaddlePaddle nhằm hỗ trợ việc nhận dạng và trích xuất thông tin từ hình ảnh. PaddleOCR ra đời hỗ trợ nhận dạng tiếng Anh, tiếng Trung, chữ số và hỗ trợ nhận dạng các văn bản dài. Hiện nay, PaddleOCR đã mở rộng thêm nhiều ngôn ngữ như Nhật, Hàn, Đức,… nhưng vẫn chưa có tiếng Việt. Văn bản tiếng Việt có dấu sẽ đọc ra không dấu, ví dụ như “Thị giác máy tính” sẽ nhận diện thành “Thi giac may tinh”. Tuy nhiên, chúng ta vẫn có thể tự huấn luyện với bộ dữ liệu riêng để PaddleOCR có thể nhận dạng được tiếng Việt.
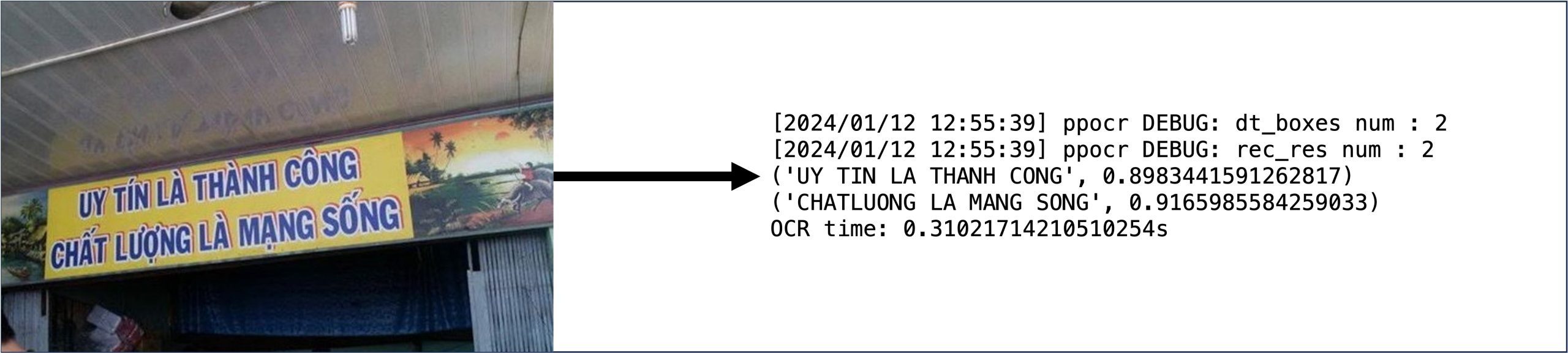
3. Các bước triển khai mô hình
Cả hai phần dectect và recognize đều gồm các bước sau:
- Bước 1: Tiền xử lý dữ liệu
- Bước 2: Cấu hình file config
- Bước 3: Train model
- Bước 4: Evaluation
- Bước 5: Convert sang model inference
- Bước 6: Predict
4. Chuẩn bị môi trường thực thi
- Bước 1: Cài đặt Python 3.7.3 x64
- Bước 2: Cài đặt Visual Studio 2015 trở lên để có Visual C++ 140 dùng để compile code
- Bước 3: Cài đặt Paddle:
- nếu sử dụng cpu:
pip install paddlepaddle - nếu sử dụng gpu rời:
pip install paddlepaddle-gpu
- nếu sử dụng cpu:
- Bước 4: Clone source code:
git clone https://github.com/thigiacmaytinh/PaddleOCR-Vietnamese.git
- Bước 5: Cài đặt một số thư viện cần thiết:
pip install -r requirements.txt
5. Mô hình detection SAST + recognition SRN
5.1. Model Detection SAST
5.1.1. Chuẩn bị dữ liệu
Bạn có thể tải tập dữ liệu huấn luyện từ repo https://github.com/VinAIResearch/dict-guided. Download dataset Original với format x1,y1,x2,y2,x3,y3,x4,y4,TRANSCRIPT. Hoặc tải tại đây.
Sau khi tải về và giải nén ra ta sẽ có:
- Folder labels – chứa các file annotation của từng image
- Folder train_images – chứa 1200 ảnh từ im0001 đến im1200
- Folder test_image – chứa 300 ảnh từ im1201 đến im1500
- Folder unseen_test_images – chứa 500 ảnh từ im1501 đến im2000
- File general_dict.txt
- File vn_dictionary.txt

image file name Image annotation information encoded by json.dumps
img_001.jpg [{“transcription”: “text”, “points”: [[31, 10], [41, 11], [48, 26], [32, 19]]}, {…}]
- points sẽ là các cặp (x, y) 4 góc của text box theo chiều ngược kim đồng hồ, bắt đầu từ góc dưới bên trái.
- transcription là text ở trong text box hiện tại. Khi chứa “###” thì có nghĩa là text box này invalid và sẽ skip đi khi train model.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import os import numpy as np from tqdm import tqdm import pandas as pd import json import glob root_path = glob.glob('./vietnamese/labels/*') train_label = open("train_label.txt","w") test_label = open("test_label.txt","w") useen_label = open("useen_label.txt","w") for file in root_path: with open(file) as f: content = f.readlines() f.close() content = [x.strip() for x in content] text = [] for i in content: label = {} i = i.split(',',8) label['transcription'] = i[-1] label['points'] = [[i[0],i[1]],[i[2],i[3]], [i[4],i[5]],[i[6],i[7]]] text.append(label) content = [] text = json.dumps(text, ensure_ascii=False) img_name = os.path.basename(file).split('.')[0].split('_')[1] int_img = int(img_name) img_name = 'im' + "{:04n}".format(int(img_name)) + '.jpg' if int_img > 1500: useen_label.write( img_name+ '\t'+f'{text}' + '\n') elif int_img > 1200: test_label.write( img_name+ '\t'+f'{text}' + '\n') else: train_label.write( img_name+ '\t'+f'{text}' + '\n') |
5.1.2. Chuẩn bị file Config
pretrained_model: ./pretrain_models/det_r50_vd_sast_icdar15_v2.0_train/best_accuracy
5.1.3. Training
|
1 |
python tools/train.py -c ./configs/det/SAST.yml |
Sau mỗi save_epoch_step, checkpoint sẽ được lưu ở đường dẫn được đặt tại dòng Global.save_model_dir trong file config gồm 3 file:
- iter_epoch_1.pdopt
- iter_epoch_1.pdparams
- iter_epoch_1.states
Ta có thể train tiếp từ checkpoint trên mà không cần sửa file config bằng cách sau:
|
1 2 |
python tools/train.py -c ./configs/det/SAST.yml \ -o Global.checkpoints=./output/SAST/iter_epoch_1 |
5.2. Model Recognition (SRN)
5.2.1. Chuẩn bị dữ liệu

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import json import os import cv2 import copy import numpy as np from paddleocr.tools.infer.utility import draw_ocr_box_txt, get_rotate_crop_image def print_draw_crop_rec_res( img_crop_list, img_name): bbox_num = len(img_crop_list) for bno in range(bbox_num): crop_name=img_name+'_'+str(bno)+'.jpg' crop_name_w = "./data/vietnamese/train/img_crop/{}".format(crop_name) cv2.imwrite(crop_name_w, img_crop_list[bno]) crop_label.write("{0}\t{1}\n".format(crop_name, text[bno])) if not os.path.exists('./data/vietnamese/train/'): os.mkdir('./data/vietnamese/train/') crop_label = open('./data/vietnamese/train/crop_label.txt','w', encoding='utf8') with open('./data/train_label.txt','r', encoding='utf8') as file_text: img_files=file_text.readlines() count=0 for img_file in img_files: content = json.loads(img_file.split('\t')[1].strip()) dt_boxes=[] text=[] for i in content: content = i['points'] if i['transcription'] == "###": count+=1 continue bb = np.array(i['points'],dtype=np.float32) dt_boxes.append(bb) text.append(i['transcription']) image_file = './data/vietnamese/train_images/' +img_file.split('\t')[0] img = cv2.imread(image_file) ori_im=img.copy() img_crop_list=[] for bno in range(len(dt_boxes)): tmp_box = copy.deepcopy(dt_boxes[bno]) img_crop = get_rotate_crop_image(ori_im, tmp_box) img_crop_list.append(img_crop) img_name = img_file.split('\t')[0].split('.')[0] if not os.path.exists('./data/vietnamese/train/img_crop'): os.mkdir('./data/vietnamese/train/img_crop') print_draw_crop_rec_res(img_crop_list,img_name) |
5.2.2. Dictionary
5.2.3. Chuẩn bị file Config
pretrained_model: ./pretrain_models/rec_r50_vd_srn_train/best_accuracy
character_dict_path: ./ppocr/utils/dict/vi_vietnam.txt
5.2.4. Training
|
1 |
python tools/train.py -c ./configs/rec/SRN.yml |
5.3. Đánh giá mô hình
|
1 2 3 |
#evaluation model detection python tools/eval.py -c ./configs/det/SAST.yml \ -o Global.checkpoints_model=./output/SAST/latest |
|
1 2 3 4 5 |
#evaluation model recognition python tools/eval.py -c ./configs/rec/SRN.yml \ -o Global.checkpoints=./output/SRN/latest \ Global.character_type=ch \ Global.character_dict_path=./ppocr/utils/dict/vi_vietnam.txt |
5.4. Inference với model đã train xong
Convert 2 mô hình dectection và recognition sang mô hình inference như sau:
|
1 2 3 4 5 6 7 8 |
# Convert mô hình dectection python tools/export_model.py -c ./configs/det/SAST.yml \ -o Global.pretrained_model=./output/SAST/latest \ Global.save_inference_dir=./inference/SAST # Convert mô hình recognition python tools/export_model.py -c ./configs/rec/SRN.yml \ -o Global.pretrained_model=./output/SRN/latest \ Global.save_inference_dir=./inference/SRN |
Sau khi convert có thể sử dụng mô hình inference để predict, kết quả sẽ được lưu tại inference_results.
|
1 2 3 4 5 |
# Predict detection python tools/infer/predict_det.py --det_algorithm="SAST" \ --use_gpu=False \ --det_model_dir="./inference/SAST" \ --image_dir="your_test_image_path" |
|
1 2 3 4 5 6 7 8 |
# Predict recognition python tools/infer/predict_rec.py --image_dir="your_test_image_path" \ --use_gpu=False \ --rec_algorithm="SRN" \ --rec_model_dir="./inference/SRN" \ --rec_image_shape="1, 64, 256" \ --rec_char_type="ch" \ --rec_char_dict_path="./ppocr/utils/dict/vi_vietnam.txt" |
Hoặc kết hợp cả 2 model detection và recognition với nhau:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
python ./tools/infer/predict_system.py \ --use_gpu=False \ --det_algorithm="SAST" \ --det_model_dir="./inference/SAST" \ --rec_algorithm="SRN" \ --rec_model_dir="./inference/SRN" \ --rec_image_shape="1, 64, 256" \ --rec_char_type="ch" \ --rec_char_dict_path="./ppocr/utils/dict/vi_vietnam.txt" \ --drop_score=0.5 \ --vis_font_path="./font-times-new-roman.ttf" \ --image_dir="your_test_image_path" |



5.5. Kết luận mô hình SAST + SRN:
Trích xuất văn bản tiếng Việt sử dụng kết hợp mô hình detection SAST và recognition SRN cho ra kết quả rất tốt, tuy nhiên thời gian detect và recognize lại tương đối chậm. Khi sử dụng CPU, thời gian cho ra kết quả là hơn 1 phút. Do đó, mô hình này không thích hợp để ứng dụng vào các bài toán trích xuất nhiều thông tin hoặc các bài toán yêu cầu tốc độ xử lý nhanh.
5.6. Tham khảo:
[AI-Challenge 2021] Nhận dạng chữ tiếng Việt trong ảnh ngoại cảnh
2 thoughts on “Sử dụng thư viện PaddleOCR trong bài toán nhận dạng chữ Tiếng Việt”
Leave a Reply
You must be logged in to post a comment.
Chào anh !
Cảm ơn anh đã chia sẻ bài viết.
Em có đang thực hiện fine tune lại theo bài viết của anh nhưng đang gặp 1 số vấn đề mong anh có thể chia sẻ.
Em có tải trained model và thử dùng trực tiếp trained model này để dự đoán tiếng anh thì kết quả ra là không có gì, nhưng khi dùng :
from paddleocr import PaddleOCR,draw_ocr
ocr = PaddleOCR( use_angle_cls=False,lang=’en’)
result = ocr.ocr(img_path, cls=False)
thì lại có kết quả tốt.
Khi thực hiện fine tune theo bài viết của anh thì có kết quả so với không có kết quả khi dùng trực tiếp trained model, nhưng kết quả ra cũng rất kém.
Em đang không biết mình bị sai ở đâu
Không biết anh có thể chia sẻ file mô hình sau fine tune của mình được không ạ
anh ơi xài paddle sao rồi, giúp em với ạ.