Giới thiệu
Machine Learning là một trong những công nghệ ảnh hưởng nhất thế giới hiện nay. Quan trọng hơn là chúng ta thấy được những tiềm năng của nó. Bài viết này sẽ giới thiệu các khái niệm về ML, bao gồm những ý tưởng cơ bản không yêu cầu trình độ cao để hiểu.
ML (máy học) là công cụ biến thông tin trở nên có giá trị kiến thức. 50 năm qua dữ liệu đã bùng nổ về dung lượng. Khối lượng data khổng lồ đó sẽ vô dụng nếu không phân tích và tìm quy luật nằm ẩn chứa bên trong. ML là kỹ thuật tự động tìm các mô hình cơ bản trong khối dữ liệu phức tạp, nếu không có ML chúng ta phải vật lộn để tìm ra. Mô hình dữ liệu là những bài toán có thể dự đoán tương lai và đưa ra các quyết định phức tạp.
Chúng ta chìm đắm trong thông tin và đói khát kiến thức – John Naisbitt
Hầu hết chúng ta đều không biết rằng đang tương tác với ML hàng ngày. Khi chúng ta tìm kiếm trên Google, nghe bài hát hoặc chụp hình thì ML đã có mặt, chúng không ngừng học hỏi và cải thiện các tương tác của người dùng. Nó cũng góp mặt trong việc thay đổi Thế giới như phát hiện ung thư, pha chế loại rượu mới hoặc là xe tự lái.
Lý do ML hấp dẫn là vì nó thoát ra khỏi các quy luật thông thường được định sẵn:
if(x = y): do z
Trước đây, kỹ sư phần mềm tập hợp các cách giải quyết của con người để giải quyết bài toán. Thay vào đó, ML tìm ra quy luật trong dữ liệu để giải quyết bài toán.
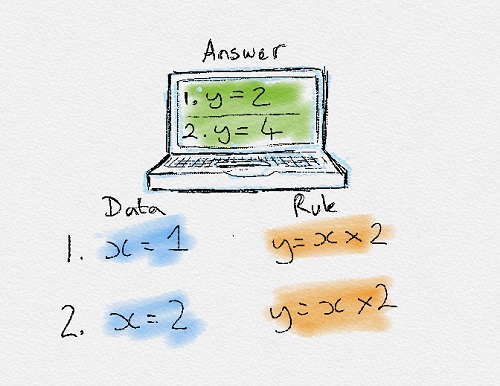
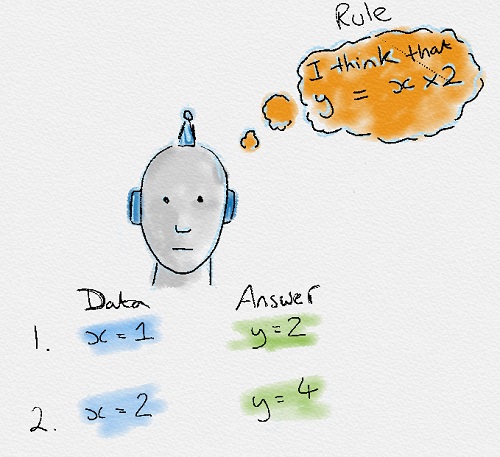
Traditional Programming vs Machine Learning
Để tìm quy tắc chi phối một hiện tượng, máy phải thông qua các bước học dữ liệu, thử các quy tắc khác nhau để tìm hiểu chúng được tạo ra thế nào. Đó là lý do gọi là Máy học.
Có nhiều hình thức của ML như: có giám sát, không giám sát, bán giám sát và học tăng cường. Mỗi hình thức của ML có cách tiếp cận khác nhau nhưng đều có chung quy trình xử lý. Bài viết này giải thích các khái niệm về ML và từng hướng tiếp cận.
Thuật ngữ
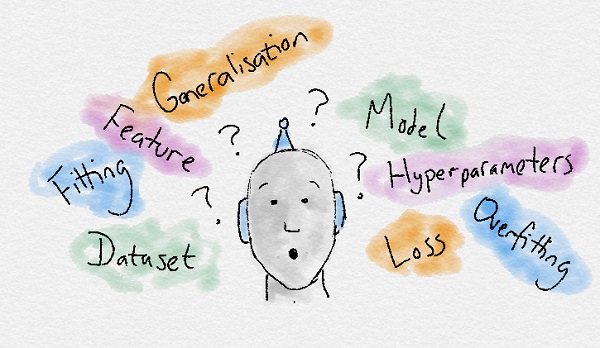
- Dataset: Bộ dữ liệu mẫu, chứa các features (đặc trưng) quan trọng để giải quyết vấn đề.
- Features: Là yếu tố chính của bài toán để giúp ML tự học.
- Model: (Mô hình) Diễn tả quy luật của dữ liệu mà ML đã học được từ data sau khi traning.
Quy trình xử lý
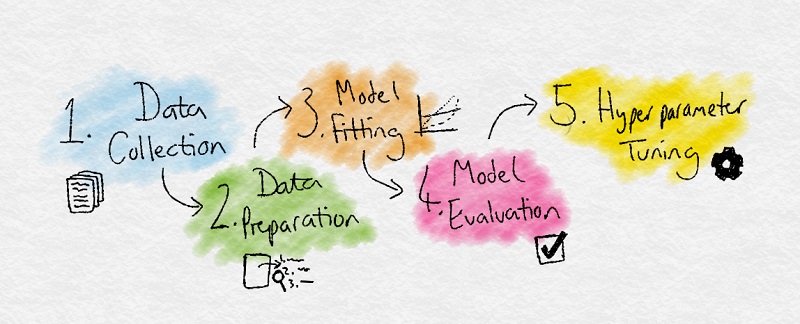
- Thu thập dữ liệu: thu thập dữ liệu để ML học
- Chuẩn bị dữ liệu:Đưa dữ liệu về chuẩn chung, trích xuất những features quan trọng và loại bỏ những thông tin không cần thiết
- Training:(còn gọi là bước sắp xếp), khi ML học từ dữ liệu đã thu thập và sắp xếp
- Đánh giá:Kiểm tra xem độ chính xác sau khi đã học (training) xong
- Tuning:Tinh chỉnh thông số để đạt được độ chính xác cao nhất
Lý thuyết nền
Nguồn gốc
Ada Lovelace, một trong những người đóng góp vào việc sáng tạo ra máy tính, có thể là lập trình viên đầu tiên nhận ra rằng mọi thứ trên thế giới có thể mô tả bằng toán học.
Điều này nghĩa là công thức toán học có thể tạo ra từ mối quan hệ giữa các hiện tượng (quy luật). Ada Lovelace thấy rằng máy móc có thể hiểu Thế giới mà không cần đến con người.
200 năm sau, những ý tưởng đó trở thành điều kiện tối quan trọng trong ML. Không quan trọng bài toán là gì, thông tin có thể vẽ trên biểu đồ dạng điểm dữ liệu. Machine Learning sau đó cố gắng tìm các mô hình toán học và các mối quan hệ ẩn trong thông tin ban đầu.
Lý thuyết xác suất

Một nhà toán học khác, Thomas Bayes, có ý tưởng rằng lý thuyết xác suất cần được áp dụng vào trong ML. (Ông nổi tiếng với giải thuật Bayes thơ ngây)
Chúng ta sống trong thế giới của xác suất, mọi thứ có thể xảy ra một cách không chắc chắn. ML phát triển dựa trên lý thuyết xác suất của Bayes, Lý thuyết này nói rằng xác suất là định lượng sự không chắc chắn của 1 sự kiện.
Vì vậy, chúng ta phải dựa trên xác suất về thông tin có sẵn của sự kiện thay vì đếm số thử nghiệm lặp lại. Ví dụ: dự đoán kết quả đá banh, thay vì đếm số lần chiến thắng của MU trước Liverpool thì chúng ta sử dụng các thông tin liên quan như: đội hình ra sân, nơi diễn ra trận đấu,…
Lợi ích của phương pháp tiếp cận này là xác suất có thể tính toán các sự kiện hiếm, vì quá trình ra quyết định dựa trên các features và lý luận có liên quan.
Các phương pháp tiếp cận ML

Có nhiều phương pháp tiếp cận và được gom theo các nhóm: Học có giám sát và không giám sát là thông dụng nhất. Bán giám sát và học tăng cường thì mới và phức tạp hơn nhưng cho kết quả ấn tượng hơn.
Lý thuyết “không có bữa trưa nào là miễn phí” cũng nổi tiếng trong ML. Nó nói rằng không có thuật toán nào là vạn năng. Mỗi bài toán đều có những đặc điểm riêng, do đó có nhiều cách giải quyết để phù hợp với từng vấn đề riêng biệt.
- Supervised Learning – Học có giám sát
- Unsupervised Learning – Học không giám sát
- Semi-supervised Learning – Học bán giám sát
- Reinforcement Learning – Học tăng cường
Học có giám sát

Trong học có giám sát, mục tiêu là tìm sự liên kết (quy luật) giữa input và output.
Ví dụ: input là dự báo thời tiết và output là khách tắm biển. Mục tiêu là tìm sự liên kết giữa nhiệt độ và số người tắm biển.
Việc gán nhãn dữ liệu cho các cặp input và output là để dạy cho máy học mô hình hoạt động thực tế, do đó gọi là học có giám sát. Ví dụ về khách tắm biển ở trên, đầu vào là nhiệt độ thời tiết và thuật toán sẽ dự báo lượng khách.
Thích ứng với bộ dữ liệu mới và đưa ra dự đoán là khái niệm tổng quát của ML. Chúng tôi luôn khái quát hóa tối đa mô hình để có thể tương thích với bất kỳ bộ dữ liệu nào. Nếu mô hình quá bám sát 1 bài toán cụ thể thì nó sẽ khó thích nghi với bài toán mới.
Lu ý trong học có giám sát là chúng ta cung cấp dữ liệu đã đánh nhãn sẵn để học. Thuật toán chỉ có thể bắt chước những gì nó đã được cung cấp, vì vậy dữ liệu phải được đánh nhãn đúng. Ngoài ra nó còn đòi hỏi rất nhiều dữ liệu để học. Thu thập dữ liệu là phần tốn nhiều công sức nhất trong học có giám sát. (Đó là lý do tại sao dữ liệu được gọi là dầu thô)
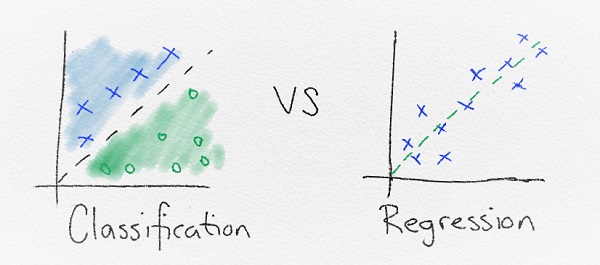
Output của học có giám sát là 1 giá trị nằm trong bộ giá trị hữu hạn. Ví dụ: [low, medium, high] là bộ kết quả của số lượng khách đi tắm biển.
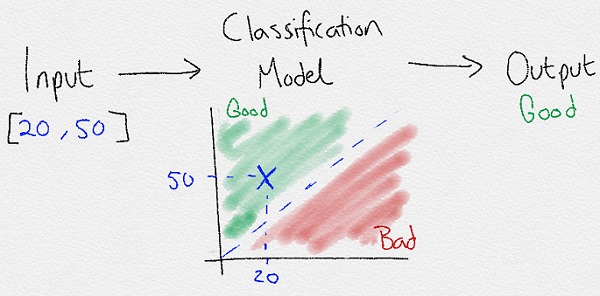
Input [temperature=20] -> Model -> Output = [visitors=high]
Trong trường hợp này, nó phân chia input vào các nhóm kết quả, nên còn được gọi là phân lớp.
Hoặc là output có thể là số lượng người tắm biển thực tế. Trong trường hợp này còn được gọi là hồi quy
Input [temperature=20] -> Model -> Output = [visitors=300]
Phân lớp
Phân lớp dùng để phân nhóm dữ liệu thành từng cụm. ML dùng để tìm quy luật giải thích vì sao lại phân chia như vậy. Có rất nhiều cách nhưng chủ yếu dựa vào dữ liệu để tìm ra quy tắc phân tách tuyến tính. Hiểu đơn giản là “phân nhóm dữ liệu bằng 1 đường thẳng”.
Đường thẳng giữa các lớp gọi là ranh giới quyết định. Toàn bộ diện tích xác định được gọi là vùng quyết định. Vùng quyết định xác định các điểm dữ liệu nằm trong nó sẽ chắc chắn thuộc 1 lớp
Hồi quy
Hồi quy là hình thức khác của học có giám sát. Sự khác biệt giữa phân lớp và hồi quy là hồi quy trả về 1 con số chứ không phải 1 lớp cụ thể. Do đó, hồi quy hữu dụng khi dự đoán con số như là chỉ số chứng khoán, nhiệt độ hoặc khả năng xảy ra sự kiện gì đó.
Ví dụ
Hồi quy dùng trong tài chính thương mại để tìm quy luật trong cổ phiếu để quyết định khi nào nên bán/mua . Trong phân lớp được dùng để phân loại email là spam hay không.
Phân lớp và hồi quy có thể mở rộng ra những công việc phức tạp khác. Ví dụ như phân tích giọng nói và âm thanh, phân loại hình ảnh, phát hiện vật thể và chatbot.
Học không giám sát
Trong học không giám sát, chỉ có dữ liệu được cung cấp mà không hề dán nhãn.

Một ví dụ trong thực tế là sắp xếp đồng xu thành từng cọc mà không ai quy định sắp xếp thế nào. Nhưng nhìn vào các đặc tính như màu sắc có thể kết hợp và gom nhóm lại.

Học không giám sát khó hơn học có giám sát, khi loại bỏ giám sát nghĩa là loại dữ liệu khó xác định hơn.
Hãy liên tưởng tới việc học của chúng ta. Nếu bạn học guitar với sự giám sát của thầy, bạn dễ dàng học hanh hơn bằng cách dùng lại kiến thức của thầy về các nốt, quãng và giai điệu. Nhưng nếu tự mày mò bạn sẽ rất khó khăn vì không biết bắt đầu từ đâu.
Khi học tự do không bị giám sát, bạn có 1 cái nhìn hoàn toàn mới và thậm chí tìm ra được cách mới, tốt hơn để giải quyết vấn đề. Do đó học không giám sát còn được gọi là khám phá kiến thức. Học không giám sát hưu dụng khi phân tích dữ liệu.
Để tìm cấu trúc của dữ liệu không được đánh nhãn, chúng ta dùng ước tính mật độ. Hình thức phổ biến nhất là gom nhóm, các cách còn lại là thu nhỏ kích thước, tìm biến tiềm ẩn và phát hiện bất thường.
Phân nhóm
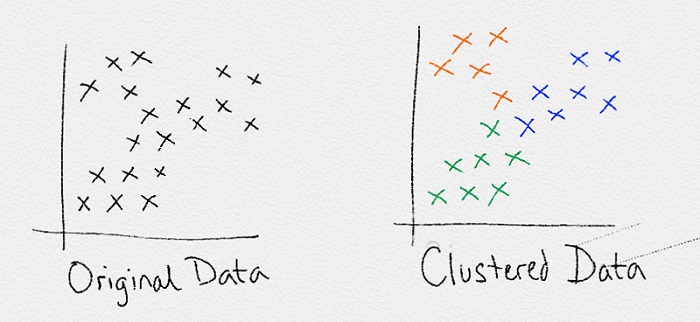
Phân nhóm được sử dụng nhiều nhất trong học không giám sát. Phân nhóm là tạo các nhóm có đặc điểm khác nhau. Do không bị giám sát nên không bị hạn chế số lượng nhãn và số lượng cụm. Nó cũng có cả ưu và nhược, chọn số cụm (độ phức tạp) phải tiến hành thông qua quy trình lựa chọn mô hình theo kinh nghiệm.
Luật kết hợp
Dùng luật kết hợp khi bạn muốn khám phá quy luật mô tả dữ liệu. Ví dụ: một người xem video A họ sẽ thích xem video B. Luật kết hợp hoàn hảo cho việc tìm những thứ có liên quan.
Phát hiện bất thường
Dùng để xác định các sự việc hiếm hoặc bất thường khác với phần lớn dữ liệu. Ví dụ: ngân hàng của bạn sẽ sử dụng để phát hiện hoạt động sai lệch trên thẻ của bạn. Thói quen chi tiêu bình thường của bạn sẽ nằm trong một phạm vi hành vi và giá trị bình thường. Nhưng khi ai đó đánh cắp thẻ của bạn rồi sử dụng thẻ thì hành vi sẽ khác với hành vi bình thường của bạn. Phát hiện bất thường sử dụng học không giám sát để cách ly và phát hiện những sự cố kỳ lạ này.
Giảm kích thước
Giảm kích thước nhằm mục đích chỉ giữ lại các đặc trưng quan trọng nhất để tạo thành một bộ data nhỏ hơn.
Ví dụ: để dự đoán số lượng khách đến bãi biển, chúng ta có thể sử dụng nhiệt độ, ngày trong tuần, tháng ,… Nhưng tháng thực sự không quan trọng để dự đoán số lượng khách nên loại bỏ cũng không sao.
Các tính năng không liên quan như có thể gây nhầm lẫn cho thuật toán của máy và làm cho chúng kém hiệu quả. Bằng cách sử dụng giảm kích thước, chỉ các tính năng quan trọng nhất được xác định và sử dụng. Phân tích thành phần chính (PCA) là một kỹ thuật thường được sử dụng.
Ví dụ
Trong thực tế, việc phân nhóm đã được sử dụng thành công trong thiên văn học. Dùng để khám phá một loại sao mới bằng cách phân tích những nhóm sao nào tự động hình thành dựa trên các đặc điểm của sao. Trong tiếp thị, nó thường được sử dụng để phân nhóm khách hàng thành các nhóm tương tự dựa trên hành vi và đặc điểm của họ.
Luật kết hợp được sử dụng để giới thiệu hoặc tìm kiếm các mục liên quan. Một ví dụ phổ biến là phân tích việc mua hàng hóa. Trong phân tích hàng hóa, các quy tắc kết hợp được tìm thấy để dự đoán các mặt hàng khác mà khách hàng có khả năng mua dựa trên những gì họ đã đặt trong giỏ hàng của họ. Amazon sử dụng điều này. Nếu bạn đặt một máy tính xách tay mới vào giỏ hàng của bạn, họ sẽ đề xuất các mặt hàng như túi chống sốc thông qua các quy tắc kết hợp của họ.
Phát hiện bất thường rất phù hợp trong các tình huống như phát hiện gian lận và phát hiện phần mềm độc hại.
Bán giám sát
Học bán giám sát là sự pha trộn giữa học giám sát và không giám sát. Quá trình học tập không được giám sát chặt chẽ như nhưng đồng thời không cho phép thuật toán tùy ý học. Học bán giám sát đi đường giữa.
Bằng cách có thể trộn lẫn một lượng nhỏ dữ liệu được gắn nhãn với bộ dữ liệu không ghi nhãn lớn hơn nhiều, nó làm giảm gánh nặng của việc có đủ dữ liệu được dán nhãn. Do đó, nó mở ra nhiều vấn đề cần giải quyết hơn với máy học.
Mạng đối thủ sáng tạo
Mạng đối thủ sáng tạo (GAN) đã là một bước đột phá gần đây với kết quả đáng kinh ngạc. GAN sử dụng hai mạng lưới thần kinh, một bộ dùng để đánh nhãn và một bộ để phân loại. Trình đánh nhãn tạo đầu ra và trình phân loại phê bình nó. Bằng cách chiến đấu với nhau, cả hai ngày càng trở nên chính xác hơn.
Khi sử dụng một mạng để tạo cả đầu vào và một mạng khác để tạo đầu ra, chúng tôi không cần phải cung cấp nhãn rõ ràng mỗi lần và do đó, nó có thể được phân loại là bán giám sát.
Ví dụ
Trong scan ung thư vú, một chuyên gia dán nhãn cho toàn bộ dữ liệu sẽ tốn thời gian và tiền bạc. Thay vào đó, một chuyên gia có thể chỉ dán nhãn cho một bộ dữ liệu ung thư vú nhỏ và thuật toán bán giám sát có thể tận dụng tập hợp nhỏ này và áp dụng nó vào một bộ dữ liệu lớn hơn.
Học tăng cường
Ít phổ biến hơn và phức tạp hơn nhiều nhưng đã tạo ra kết quả đáng kinh ngạc. Nó không sử dụng nhãn như các loại trên, và thay vào đó sử dụng phần thưởng để học.
Nếu bạn quen thuộc với tâm lý học, bạn sẽ nghe nói về học tập củng cố. Trong phương pháp này, thỉnh thoảng phản hồi tích cực và tiêu cực được sử dụng để củng cố các hành vi. Hãy nghĩ về nó giống như huấn luyện một con chó, những hành vi tốt được thưởng bằng một điều trị và trở nên phổ biến hơn. Những hành vi xấu bị trừng phạt và trở nên ít phổ biến hơn. Hành vi có động cơ khen thưởng này là chìa khóa trong học tập củng cố.
Điều này rất giống với cách chúng ta học. Trong suốt cuộc đời, chúng ta nhận được tín hiệu tích cực và tiêu cực và không ngừng học hỏi từ chúng. Các hóa chất trong não của chúng ta là một trong nhiều cách chúng ta có được những tín hiệu này. Khi điều gì đó tốt xảy ra, các tế bào thần kinh trong não của chúng ta cung cấp một lượng lớn các chất dẫn truyền thần kinh tích cực như dopamine khiến chúng ta cảm thấy tốt và chúng ta có nhiều khả năng lặp lại hành động cụ thể đó. Chúng tôi không cần giám sát liên tục để học như trong học có giám sát. Bằng cách chỉ đưa ra các tín hiệu gia cố không thường xuyên, chúng ta vẫn học rất hiệu quả.
Ví dụ
Học tăng cường đã được sử dụng nhiều trong thế giới thực do nó mới và phức tạp như thế nào. Nhưng một ví dụ trong thế giới thực là sử dụng học tăng cường để giảm chi phí vận hành trung tâm dữ liệu bằng cách kiểm soát các hệ thống làm mát theo cách hiệu quả hơn. Thuật toán học một chính sách tối ưu về cách hành động để có được chi phí năng lượng thấp nhất. Chi phí càng thấp, phần thưởng nhận được càng nhiều.
Google DeepMind đã sử dụng học tập tăng cường trong nghiên cứu để chơi các trò chơi Go và Atari ở cấp độ siêu phàm.
Tác giả: Gavin Edwards
Nguồn: https://towardsdatascience.com/machine-learning-an-introduction-23b84d51e6d0