Thư viện Paddle nhận diện ký tự tượng hình rất tốt nên nhận diện tiếng Hàn Quốc cho kết quả rất chính xác. Bài viết này giới thiệu khả năng và hướng dẫn cách sử dụng thư viện bằng ngôn ngữ Python.
Đầu tiên là giới thiệu đến các bạn 1 số kết quả nhận diện tiếng Hàn Quốc trên phim.
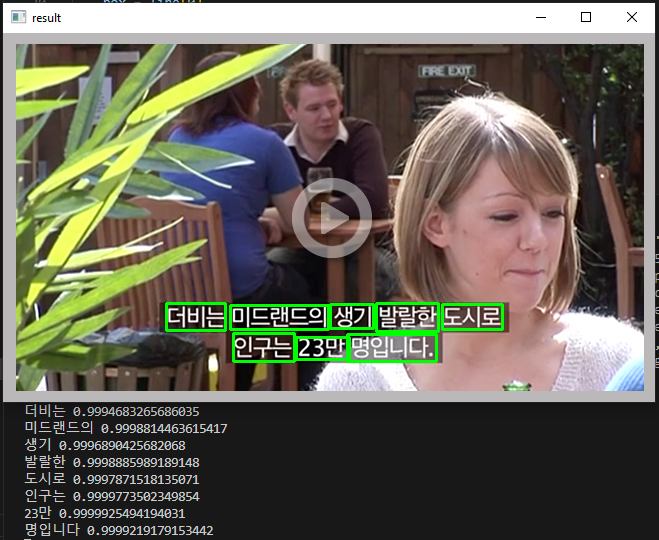
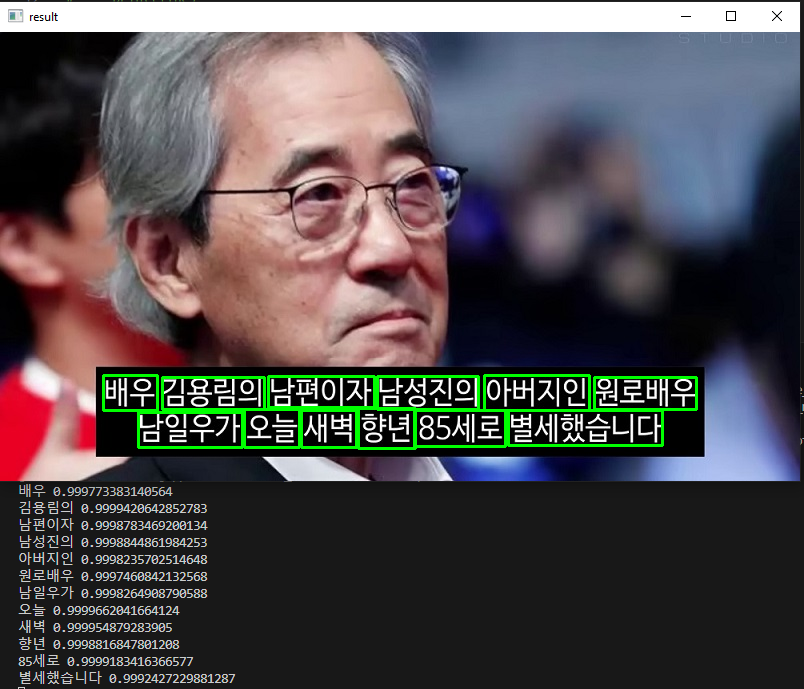
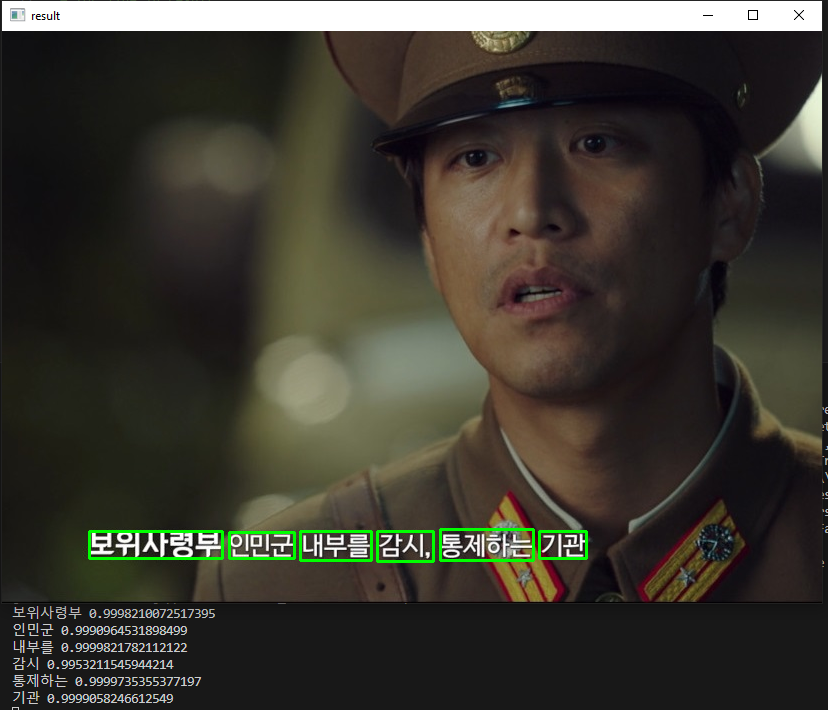
Hướng dẫn cài đặt và sử dụng
Bài viết này sử dụng máy tính với các thông số như sau:
- Windows 10 x64
- Python 3.7.3 x64
Bước 1: cài đặt thư viện PaddlePaddle
Cài đặt đúng version 2.4.2
python -m pip install --force-reinstall paddlepaddle==2.4.2
Bước 2: clone thư viện Paddle OCR
Clone PaddleOCR ở link: https://github.com/PaddlePaddle/PaddleOCR
Cài đặt các thư viện cần thiết:
pip install -r requirements.txt
Bước 3: viết code để nhận diện ký tự và vẽ bounding box
Sau đó tạo 1 file test.py với nội dung như bên dưới
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
from paddleocr import PaddleOCR import cv2 # Also switch the language by modifying the lang parameter ocr = PaddleOCR(lang="korean") # The model file will be downloaded automatically when executed for the first time img_path = 'input.jpg' result = ocr.ocr(img_path)[0] mat = cv2.imread(img_path) for line in result: #print(line) box = line[0] #print(score) text, score = line[1] print(text, score) top_left, top_right, bottom_right, bottom_left = box top_left = (int(top_left[0]), int(top_left[1])) bottom_right = (int(bottom_right[0]), int(bottom_right[1])) cv2.rectangle(mat, top_left, bottom_right, (0, 255, 0), 2) cv2.imshow("result", mat) cv2.waitKey(0) |
Có nhiều ngôn ngữ để lựa chọn như: ‘ch’, ‘en’, ‘korean’, ‘japan’, ‘chinese_cht’, ‘ta’, ‘te’, ‘ka’, ‘latin’, ‘arabic’, ‘cyrillic’, ‘devanagari’
Chúc các bạn thành công!