Bài viết này hướng dẫn các bạn huấn luyện YOLOv7 phát hiện cà chua tốt (OK) và hư (NG – Not Good).
Yêu cầu phần cứng tối thiểu:
- Hệ điều hành: Windows 10
- RAM: Tối thiểu 16GB
- GPU: NVIDA 6GB VRAM
- CPU: Intel Core i5 4590 hoặc tương đương
Bài viết này hướng dẫn train trên local PC. Nếu phần cứng không đáp ứng được yêu cầu đưa ra, bạn vẫn có thể sử dụng công cụ hỗ trợ như Google Colab.
Tổng quan các bước cần thực hiện
- Thu thập dữ liệu và gắn nhãn cho ảnh.
- Tiến hành quá trình training cho model.
- Kiểm tra kết quả ta vừa thực hiện.
Bước 1: Thu thập dữ liệu và gắn nhãn cho ảnh
Bạn cần chuẩn bị đầy đủ tập dữ để hệ thống có thể nhận biết được đâu là cà chua tốt và hư. Trong dự án này, mình đặt tên cho 2 classes tương ứng cho cà chua tốt và hư lần lượt là OK và NG.
Để gán nhãn cho ảnh, ta có thể sử dụng tool Darknet Locator

Data để train, mình lưu vào folder yolov7\data\tomato\train\images
Bước 2: Tiến hành quá trình training cho model
Cài đặt phần mềm
- CUDA 11.3
- cuDNN 8.2.1: Restart PC sau khi cài xong
- Python 3.7.3 x64: Restart PC sau khi cài xong
- Visual Studio Code và extension Jupiter Notebook
Cài đặt các package cần thiết
Trong folder source code có file requirements.txt, các bạn có thể cài đặt bằng lệnh:
pip install -r requirements.txt
Restart PC sau khi cài xong.
Cài đặt Pytorch và file pretrain YOLOv7
Cài đặt Pytorch CUDA 11.3
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
Restart PC sau khi cài xong.
Download yolov7.pt và lưu vào folder chứa source code.
Trong folder source code đã có sẵn hình ảnh và nhãn. Hình ảnh quả cà chua trong folder tomato. Trong đây có file data.yaml định nghĩa dữ liệu với 2 classes và folder chứa ảnh.
OK: Cà chua tốt, NG (Not Good): Cà chua hư
Mở file yolov7_training.ipynb lên, chạy block Training Yolov7. Thời gian training theo cấu hình ở trên là gần … giờ, kết quả đạt được là file best.pt.
Bước 3: Kiểm tra kết quả ta vừa thực hiện
Kết quả sau khi train xong
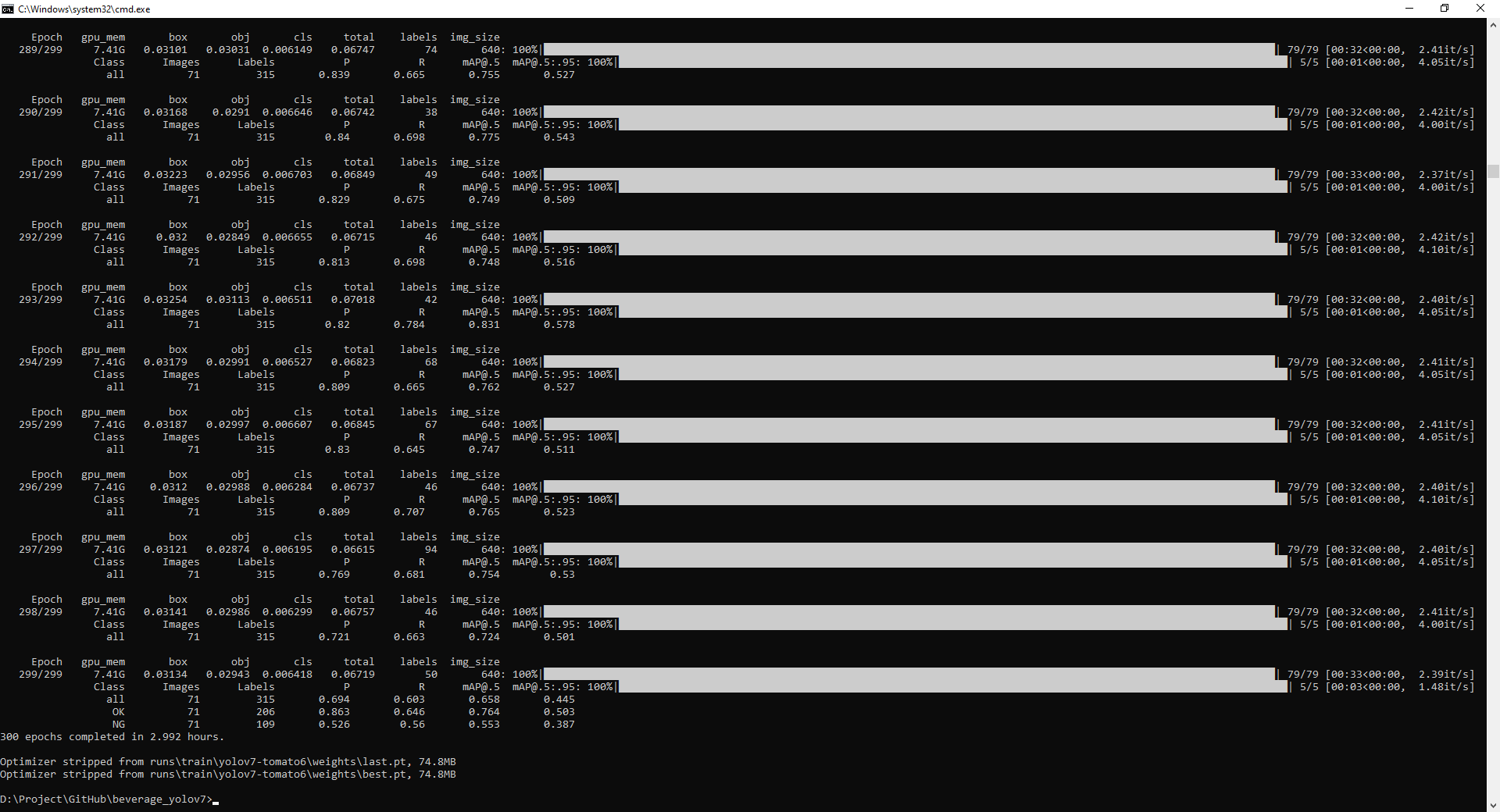
Sau khi training lần đầu, kết quả vẫn chưa chính xác hoàn toàn. Vì vậy, ta cần training lại cho model bằng cách thêm dữ liệu hoặc lặp lại các bức ảnh mà model chưa học kỹ.
Sau vài lần training, ta có được trọng số có kết quả tốt nhất và tiến hành kiểm tra kết quả.
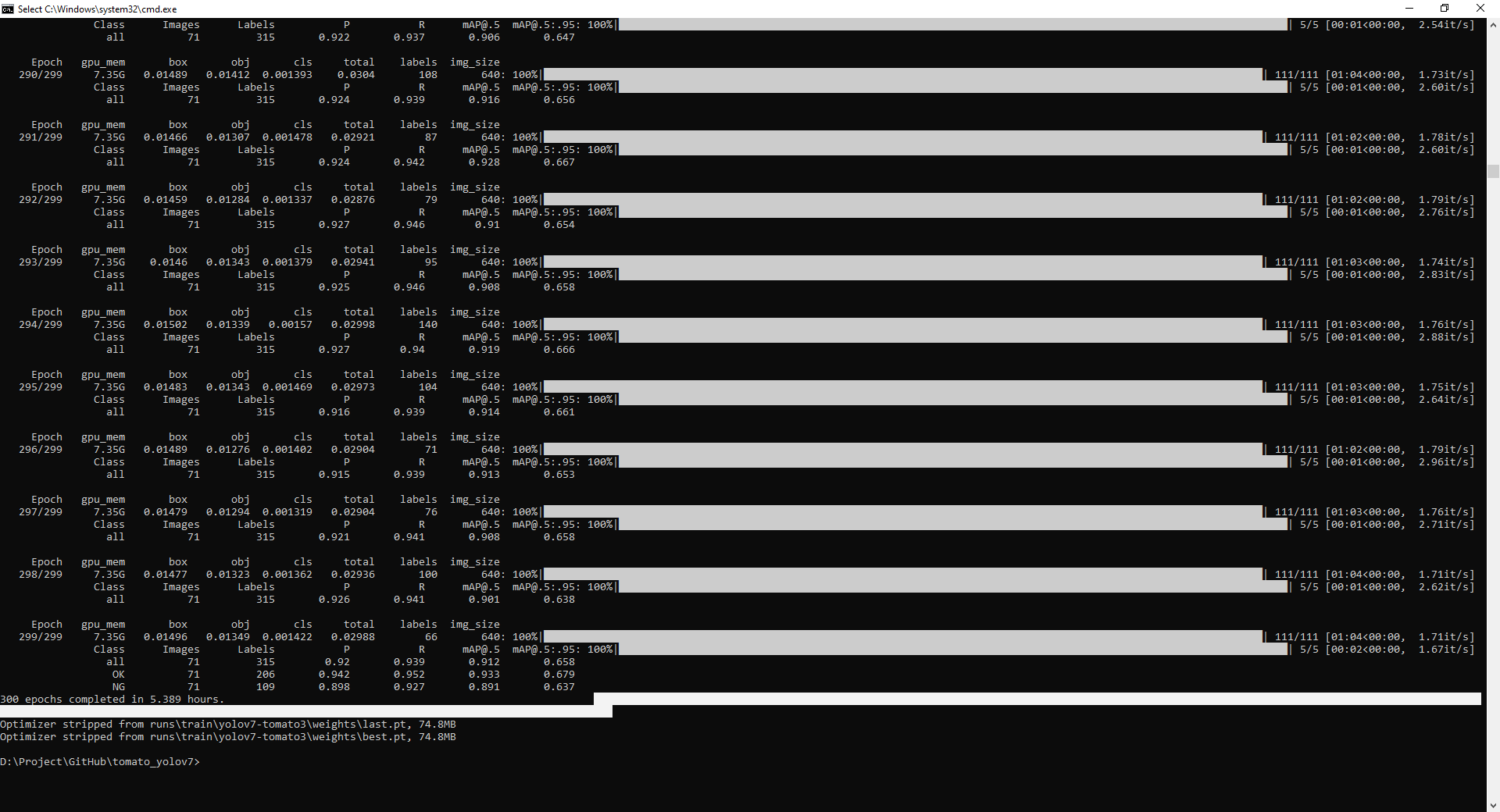
Trong file yolov7_training.ipynb, ta chạy block Evalution để inference hình ảnh. Bên dưới là 1 ảnh kết quả.

Bài viết trên chỉ mang tính chất tham khảo và hướng dẫn bạn cách train cho model bằng YOLOv7. Nếu muốn làm cho model trở nên tối ưu thì hãy thu thập nhiều dữ liệu hơn và làm lại các bước mà mình đã hướng dẫn.
Trong trường hợp VRAM không đủ, ta có thể giảm batch size xuống còn 4.