PaddleOCR là một thư viện OCR mã nguồn mở được phát triển bởi Baidu PaddlePaddle. Thư viện này cho ra kết quả chính xác với tốc độ rất nhanh. Bài viết này sẽ hướng dẫn fine-turning mô hình recognition của PaddleOCR với bộ data của riêng bạn.
Nếu bạn chỉ cần sử dụng mô hình PaddleOCR cơ bản có thể tham khảo bài viết Xác định vị trí của text trong ảnh bằng PaddleOCR.
1. Chuẩn bị môi trường:
- Hệ điều hành: Windows 10
- Python:
Trong bài viết này, chúng tôi sử dụng python phiên bản 3.8.0. - Phiên bản PaddleOCR:
git clone https://github.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR
git checkout release/2.6 - Các thư viện cần thiết:
- Cài đặt các python packages trong requirements của repo PaddleOCR:
pip install -r requirements.txt - Cài đặt paddlepaddle-gpu để train:
pip install paddlepaddle-gpu
- Cài đặt các python packages trong requirements của repo PaddleOCR:
2. Chuẩn bị dataset
- Số lượng:
Để khái quát hóa dữ liệu tốt hơn cho việc fine-turning mô hình, các bạn nên chuẩn bị ít nhất 10.000-15.000 ảnh. Nếu không khả thi, các bạn có thể thử với 3.000-5.000 ảnh.
Theo document của PaddleOCR, để train đạt kết quả tốt, dữ liệu cần hàng trăm ngàn cho mô hình Tiếng Anh. Đối với các ngôn ngữ phức tạp, con số này có thể lên đến hàng triệu.
- Format:
Dataset có cấu trúc như sau:
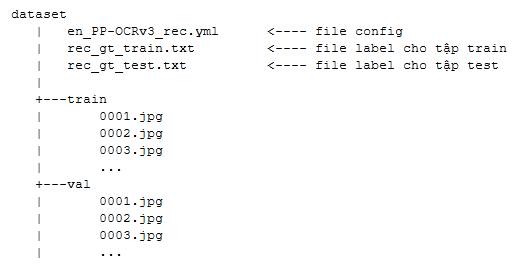
Format của file label: PaddleOCR yêu cầu label theo format ICDAR.

Tiếp đến các bạn điều chỉnh đường dẫn tương ứng của dataset trong file config tại phần Train và Eval:

- Độ đa dạng:
Dữ liệu nên bao gồm nhiều font chữ, cỡ chữ, màu sắc, góc độ khác nhau. Điều kiện ánh sáng, độ phân giải ảnh khác nhau cũng sẽ góp phần làm đa dạng dữ liệu hơn.
3. Chuẩn bị train mô hình:
1. Download pretrain model
2. Chuẩn bị dictionary
File dictionary sử dụng trong bài viết nằm ở ppocr/utils/dict/en_dict.txt Các bạn có thể dùng dictionary có sẵn hoặc tự tạo file có cấu trúc tương tự đều được.
3. Config
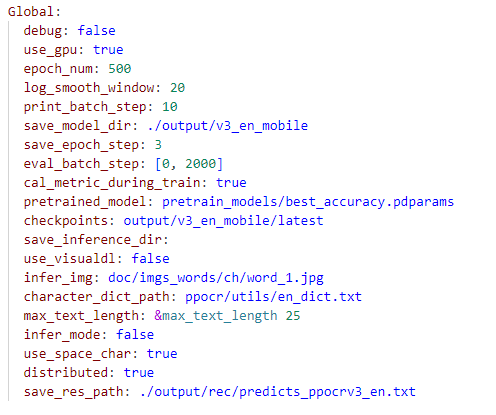
Nếu train từ đầu thì bỏ trống dòng checkpoints.
4. Train mô hình
python ./tools/train.py -c dataset/en_PP-OCRv3_rec.yml
5. Export model để inference
python tools/export_model.py -c dataset/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./output/v3_en_mobile/best_accuracy Global.save_inference_dir=./inference/
Tham khảo
PaddleOCR:
Chúc các bạn thành công!