Trong bài toán nhận diện khuôn mặt, việc khuôn mặt không nhìn trực diện có thể dẫn đến kết quả nhận diện kém. Do đó cần phải có bước xử lý để xác dịnh khuôn mặt có đang ở hướng trực diện hay không. Trong bài viết này, chúng tôi sẽ hướng dẫn sử dụng SVM để dự đoán hướng khuôn mặt bằng Python.
Trong website thigiacmaytinh.com đã có hướng dẫn xác định góc bằng cách xác định tọa độ các điểm. Tuy nhiên thuật toán này quá đơn giản dẫn đến nhiều trường hợp bị sai. Bài viết này tích hợp SVM để cho ra kết quả nhận diện hướng nhìn chính xác trên 99%.
Phần 1: Lý thuyết
1. Giới thiệu về thuật toán SVM
SVM (Support Vector Machine) là một trong những thuật toán học máy được sử dụng phổ biến cho các bài toán phân loại và hồi quy. Mục tiêu của SVM là tìm một siêu phẳng (hyperplane) tối ưu để phân tách dữ liệu thành các nhóm riêng biệt trong không gian đa chiều.
Siêu phẳng tối ưu là một siêu phẳng mà khoảng cách (margin) giữa siêu phẳng đó và những điểm dữ liệu gần nó nhất (các support vectors) là lớn nhất.
SVM tìm siêu phẳng tối ưu bằng cách giải một bài toán tối ưu hóa. Nó cần tìm một siêu phẳng có phương trình dạng:
𝑤⋅𝑥 + 𝑏 = 0
Trong đó:
- 𝑤 là vector trọng số (weight vector) vuông góc với siêu phẳng.
- 𝑥 là điểm dữ liệu.
- 𝑏 là bias (độ dời của siêu phẳng so với gốc tọa độ).
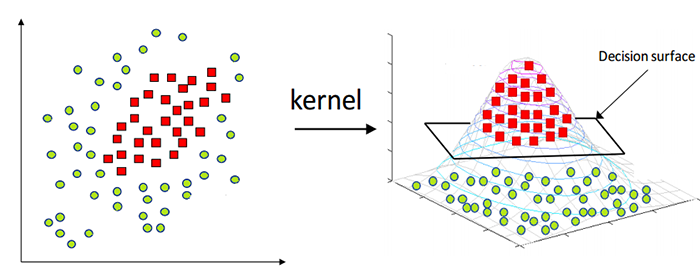
✅ Lý do chọn SVM là vì tốc độ nhanh & kết quả chính xác.
Bài viết này sử dụng thư viện Scikit-learn để implement thuật toán SVM
2. Giới thiệu về Facemesh
Facemesh hay còn gọi là landmark là tập hợp các điểm (point) trên khuôn mặt. Thư viện mediapipe cung cấp function detect 468 điểm trên khuôn mặt rất nhanh & chính xác.
Đọc thêm về Facemesh tại: https://thigiacmaytinh.com/phat-hien-cu-dong-khuon-mat-bang-facemesh/
Trong thư viện Mediapipe mỗi điểm gồm 3 giá trị x, y, z trong không gian 3 chiều. Tuy nhiên chỉ cần x, y là đủ để phát hiện hướng nhìn, không cần đến z.
Dữ liệu mà SVM chấp nhận là array có giá trị từ 0-255, tuy nhiên mesh detect được có giá trị x, y từ 0->image width và 0->image height. Vì vậy cần normalize mesh về giá trị 0-255 để SVM chấp nhận.

Đầu tiên bạn cần resize facemesh về 256px, sau đó tịnh tiến về gốc tọa độ để giá trị x,y của mesh nằm trong khoảng 0-255.
Sau đó bạn cần nối các điểm của facemesh thành vector theo thứ tự, với 0 là class ID
x0 y 0x1 y1 x2 y2 x3 y3....x467 y467
Phần 2: thu thập dữ liệu khuôn mặt
Để training được hướng nhìn bạn cần tạo 5 folder với 5 hướng nhìn: Straight, Up, Down, Left, Right. Tương ứng là 5 class ID 0,1,2,3,4.

Số lượng ảnh cần khoảng 30 ảnh cho mỗi class, sau đó trong quá trình thử nghiệm nếu nhìn sai thì cần bổ sung tiếp.
Các bạn cần tạo matrix data với số lượng dòng bằng số lượng ảnh, số lượng cột bằng 468 x 2 = 936 (1 point có 2 giá trị) để training.
Và 1 mảng labels chứa class ID, là số đầu tiên của folder.
Phần 3: Hướng dẫn thực hiện
Chuẩn bị
- Cài đặt Python 3.8.0
- Cài đặt Visual Studio Code
- Cài đăt các packages cần thiết: opencv-python, scikit-learn, numpy, mediapipe, pickle
pip install scikit-learn, opencv-python, numpy, mediapipe, pickle
Thực hiện
Full code ở cuối bài viết
- Khởi tạo Mediapipe FaceMesh
12345678# Initialize Mediapipe FaceMeshimport mediapipe as mpmp_face_mesh = mp.solutions.face_meshface_mesh = mp_face_mesh.FaceMesh(static_image_mode=False,max_num_faces=1,refine_landmarks=False,min_detection_confidence=0.5) - Trích xuất 468 điểm của Face Landmarks bằng MediaPipe
Bước này tìm facemesh và normalize về giá trị SVM chấp nhận.
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152import cv2import numpy as npdef extract_face_landmarks(frame):landmarks = []image_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)result = face_mesh.process(image_rgb)frame_height, frame_width, _ = frame.shapeif result.multi_face_landmarks:for face_landmarks in result.multi_face_landmarks:# Extract the 468 landmarksleft, top = frame_width, frame_heightright, bottom = 0, 0for point in face_landmarks.landmark:x = int(point.x * frame_width)y = int(point.y * frame_height)# Update the bounding box coordinatesif x < left:left = int(x)if y < top:top = int(y)if x > right:right = int(x)if y > bottom:bottom = int(y)width = right - leftheight = bottom - topif (width > height):top -= (int)(width - height) / 2height = widthelse:left -= (int)(height - width) / 2width = heightratio = float(width) / 256for point in face_landmarks.landmark:_x = float(point.x * frame_width - left) / ratio_y = float(point.y * frame_height - top) / ratiolandmarks.append([int(_x), int(_y)]) # x, y coordinates (normalized)if (landmarks):return np.array(landmarks).flatten()else:return None - Load ảnh và labels
Bước này load tất cả ảnh trong 5 folder và tạo thành 2 array để training
123456789101112131415161718192021222324import osdef load_images_and_landmarks(dataset_dir):images = []labels = []for folder_name in os.listdir(dataset_dir):folder_path = os.path.join(dataset_dir, folder_name)if not os.path.isdir(folder_path):continueclass_index, class_name = folder_name.split('.')for img_name in os.listdir(folder_path):img_path = os.path.join(folder_path, img_name)img = cv2.imread(img_path)landmarks = extract_face_landmarks(img)if landmarks is not None:images.append(landmarks)labels.append(int(class_index))else:print(img_name)return np.array(images), np.array(labels) - Training SVM model
Training và save model, test độ chính xác của model, đạt hơn 99% là được.
12345678910111213141516171819from sklearn.svm import SVCimport pickledef train_svm(X_train, y_train):svm_model = SVC(kernel='linear') # You can change the kernel type as neededsvm_model.fit(X_train, y_train)return svm_model# Save the modeldef save_model(svm_model, filename):with open(filename, 'wb') as f:pickle.dump(svm_model, f)# Load the modeldef load_model(filename):with open(filename, 'rb') as f:svm_model = pickle.load(f)print(f"Model loaded from {filename}")return svm_model - Train model
1234567891011121314151617181920212223242526from sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_scoredataset_dir = r'D:\Data.ML\faceset\FaceDirection' # Update this path to your datasetmodel_filename = 'svm_face_direction.xml' # Specify your desired filenameclass_names = ['straight', 'up', 'down', 'left', 'right', 'open mouth'] # Add your classes# Load dataset# Load dataset and extract 468 landmarksimages, labels = load_images_and_landmarks(dataset_dir)# Split into training and test setX_train, X_test, y_train, y_test = train_test_split(images, labels, test_size=0.2, random_state=42)# Train the SVM modelsvm_model = train_svm(X_train, y_train)# Save the trained model to XMLsave_model(svm_model, model_filename)# Load the model back from the XML fileloaded_svm_model = load_model(model_filename)# Evaluate the loaded model on the test sety_pred = loaded_svm_model.predict(X_test)print(f"Accuracy with loaded model: {accuracy_score(y_test, y_pred) * 100:.2f}%") - Test bằng webcam
12345678910111213141516171819202122232425262728# 4. Test with Camera and Predict using SVM Modeldef test_with_camera(svm_model, class_names):cap = cv2.VideoCapture(0)while True:ret, frame = cap.read()if not ret:break# Extract landmarks from the live video framelandmarks = extract_face_landmarks(frame)if landmarks is not None:landmarks = landmarks.reshape(1, -1) # Reshape for predictionprediction = svm_model.predict(landmarks)predicted_class = class_names[prediction[0]]# Display the predicted class on the framecv2.putText(frame, f"Prediction: {predicted_class}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)cv2.imshow('Camera Feed', frame)if cv2.waitKey(1) & 0xFF == ord('q'):breakcap.release()cv2.destroyAllWindows()test_with_camera(loaded_svm_model, class_names)