Nhận diện văn bản tiếng Anh là OCR (Optical Character Recognition). Chuyên dùng để đọc các ký tự trong ảnh rồi chuyển thành text để giảm công sức đánh máy. Trong đó phổ biến nhất là nhận diện văn bản bằng Tesseract.
Cũng như các ứng dụng Thị giác máy tính khác, nhận diện là bước cuối cùng. Các bạn nên xử lý cho hình ảnh rõ ràng, dễ đọc trước khi đưa vào nhận diện
Giới thiệu
Tesseract là thư viện OCR nổi tiếng do độ chính xác cao hơn hẳn các thư viện khác. Tesseract có thể chạy độc lập hoặc tích hợp với OpenCV đều được. Nếu chạy độc lập thì Tesseract sử dụng thư viện leptonica để đọc hình ảnh.
Github của Tesseract: https://github.com/tesseract-ocr/tesseract
Data đã training của Tesseract: https://github.com/tesseract-ocr/tessdata. Có sẵn tiếng Việt, tiếng Anh, tiếng Đức cho nhu cầu thông thường.
Bên dưới là ảnh để test và kết quả đọc được:

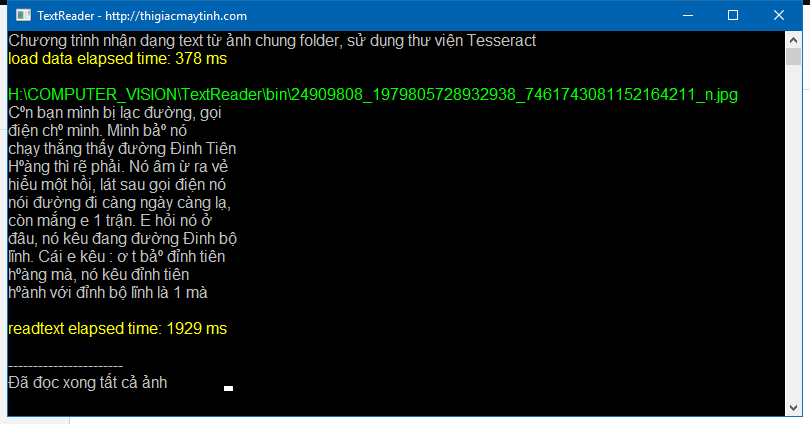
Video demo
Hướng dẫn sử dụng
- Sử dụng Visual Studio 2015 trở lên
- Clone source code ở link cuối bài
- Build solution, có phiên bản console C++ và UI viết bằng C#