- Tổng quan về YOLO cho người mới bắt đầu
Mục lục
- Tổng quan về Phát hiện đối tượng
- You Only Look Once
- Tại sao lại là v8
- Các phiên bản của mô hình YOLOv8
- Hướng dẫn sử dụng
- Câu hỏi thường gặp
1. Tổng quan về Phát hiện đối tượng
Phát hiện đối tượng hay Object Detection là một tác vụ trong lĩnh vực Thị giác máy tính (Computer Vision) nhằm mục đích phát hiện và xác định vị trí của các đối tượng cụ thể trong hình ảnh hoặc video. Tác vụ này bao gồm việc xác định vị trí cũng như ranh giới của các đối tượng trong hình ảnh và phân loại các đối tượng. Nó là một phần quan trọng của nhận dạng thị giác, bên cạnh phân loại và truy xuất hình ảnh.
Các phương pháp hiện đại có thể phân ra thành 2 loại chính: one-stage và two-stage:
- One-stage: ưu tiên tốc độ suy luận (inference speed), ví dụ như YOLO, SSD, RetinaNet
- Two-stage: ưu tiên độ chính xác của việc phát hiện (detection accuracy), ví dụ như Faster R-CNN, Mask R-CNN, Cascade R-CNN.
Các mô hình thường được đánh giá trên tập dữ liệu MS COCO, dựa trên chỉ số Độ chính xác trung bình (Mean Average Precision – mAP).
YOLO hỗ trợ các bài toán về xử lý hình ảnh gồm:
- Detection: Trả lời câu hỏi “Trong ảnh có những gì và ở đâu?”
- Segmentation: Trả lời câu hỏi “Đối tượng chiếm những pixel nào?”
- Classification: Trả lời câu hỏi “Ảnh này là gì?”
- Pose: Trả lời câu hỏi “Cấu trúc/hình dạng chuyển động của đối tượng như thế nào?”
1.a Object Detection (Phát hiện đối tượng)

Chức năng là xác định vị trí và loại của các đối tượng trong ảnh. Kết quả trả về gồm có:
- Bounding Box: tọa độ hình chữ nhật bao quanh đối tượng
- Class: nhãn đối tượng, ví dụ: person, car, dog…
- Confidence Score: độ tin cậy dự đoán, trong thực tế ứng dụng sẽ lấy object có score từ 0.8 trở lên
Tuy nhiên chỉ xác định vùng chữ nhật bao quanh, không phân biệt chi tiết hình dạng bên trong.
1.b Segmentation (Phân đoạn ảnh)
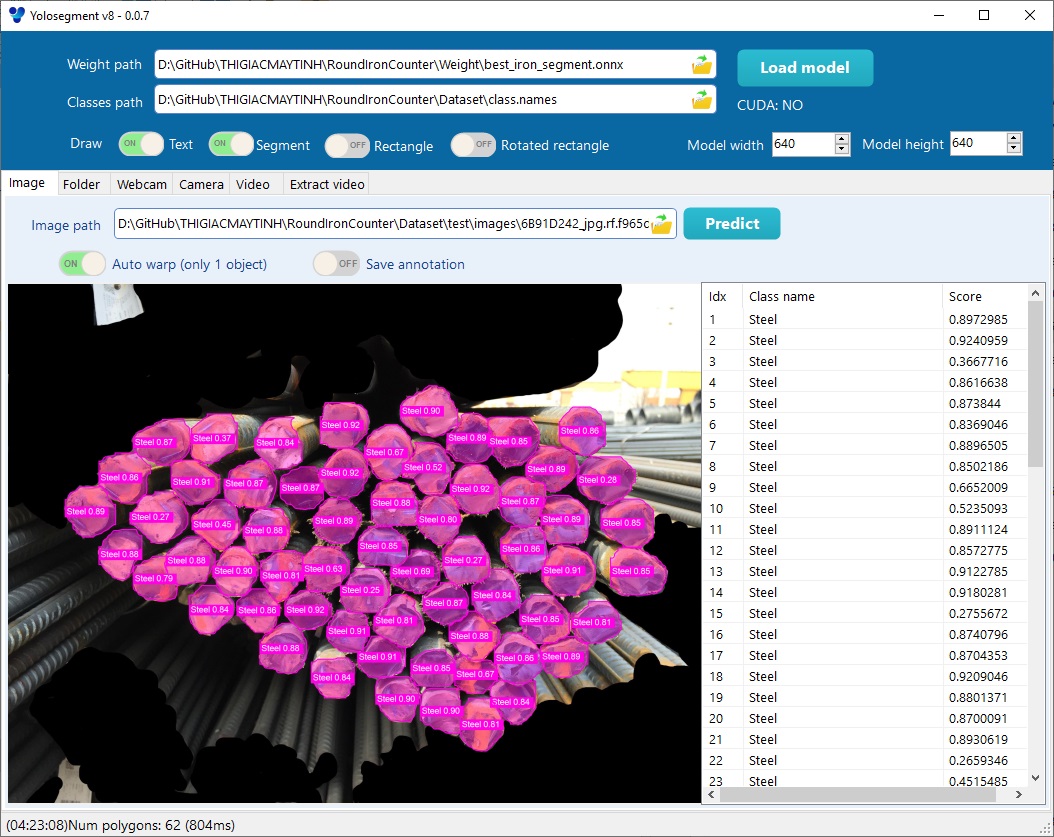
Chức năng là xác định chính xác từng pixel thuộc về đối tượng nào. Kết quả trả về gồm có:
- Mask: là danh sách các pixel chứa đối tượng List(x,y)
- Class: tương tự detection
- Confidence Score: tương tự detection
Bounding box tự tìm bằng cách viết vòng lặp tìm minX, minY, maxX và maxY.
Đặc điểm nổi bật là chính xác hơn detection về mặt hình dạng, bù lại sẽ chậm hơn detection 1 chút.
1.c Classification (Phân loại ảnh)

Chức năng là xác định toàn bộ hình ảnh thuộc lớp nào, phù hợp để phân loại các object đã crop. VD như khuôn mặt có đeo khẩu trang không?
Kết quả trả về:
- Class: tương tự detection
- Confidence Score: tương tự detection
Đặc điểm là không xác định vị trí đối tượng mà chỉ trả về nhãn chung cho toàn ảnh nên nhẹ và đơn giản nhất trong 4 chức năng.
1.d Pose Estimation (Ước lượng tư thế)
Chức năng là xác định các điểm keypoints (điểm đặc trưng) trên cơ thể người hoặc vật thể.
Kết quả trả về là tọa độ các keypoints (ví dụ: vai, khuỷu tay, đầu gối…) kèm Confidence Score cho từng điểm.

Dùng trong phân tích hành vi, thể thao, theo dõi chuyển động. Không chỉ phát hiện người mà còn mô tả cấu trúc hình học của cơ thể.
2. “You Only Look Once”
You Only Look Once hay YOLO là một thuật toán phát hiện đối tượng thời gian thực tiên tiến, được giới thiệu vào năm 2015 bởi Joseph Redmon, Santosh Divvala, Ross Girshick, và Ali Farhadi trong bài báo nghiên cứu nổi tiếng của họ có tên “You Only Look Once: Unified, Real-Time Object Detection”.
Các tác giả đã định hình bài toán phát hiện đối tượng như một bài toán hồi quy thay vì bài toán phân loại, bằng cách tách không gian các hộp giới hạn (bounding boxes) và gán xác suất cho từng đối tượng được phát hiện bằng cách sử dụng một mạng nơ-ron tích chập (CNN) duy nhất.
Điểm đặc trưng của YOLO là khả năng thực hiện dự đoán toàn bộ hình ảnh trong một lần xử lý, giúp tăng tốc độ đáng kể so với các mô hình truyền thống khác như R-CNN hoặc Faster R-CNN, vốn yêu cầu thực hiện nhiều bước xử lý cho mỗi khung hình.
Kể từ khi phiên bản đầu tiên của YOLO ra mắt vào năm 2015, nó đã phát triển rất nhiều với các phiên bản khác nhau.
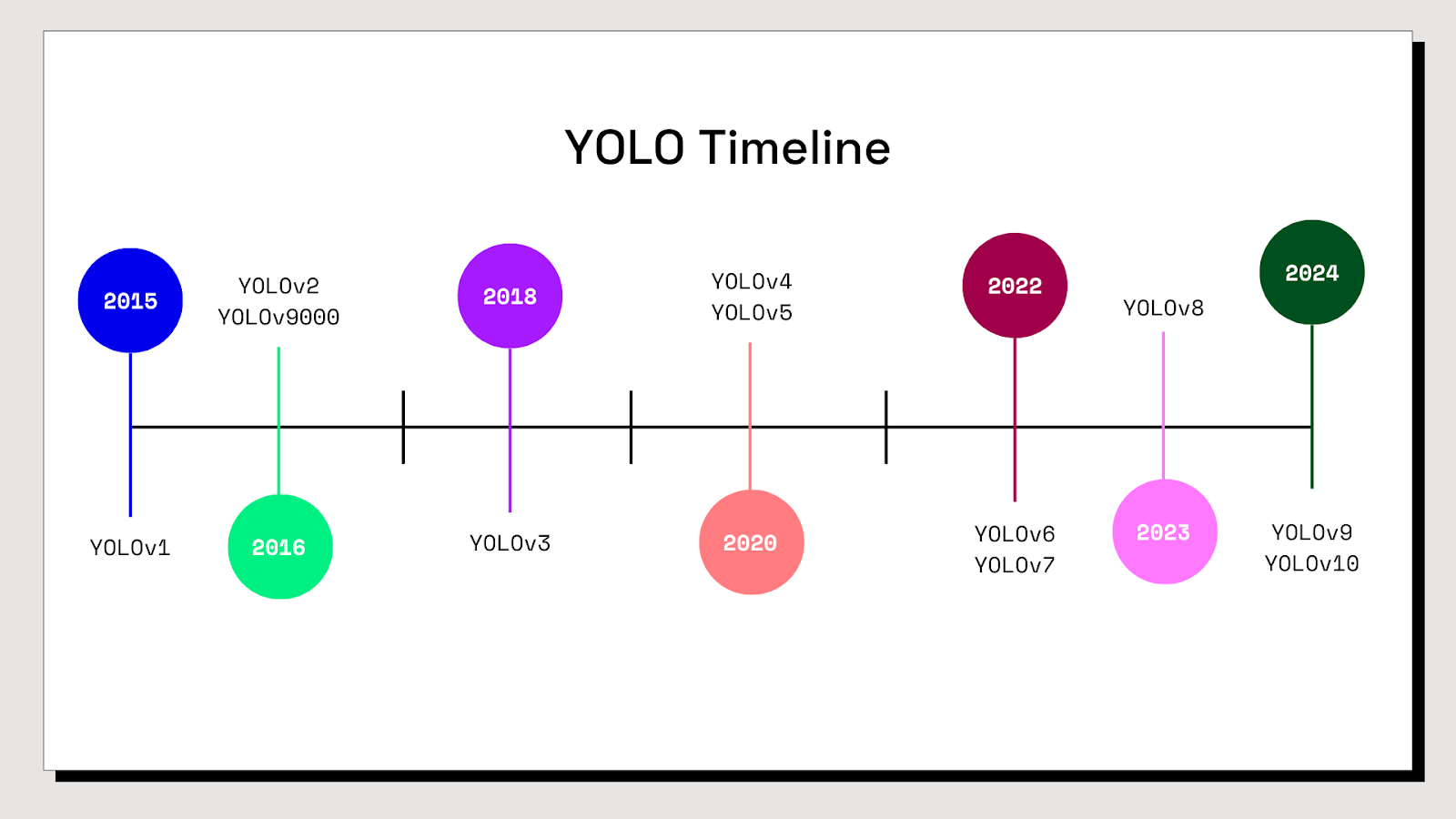
3. Tại sao lại là v8?
YOLOv8 phiên bản mới nhất trong YOLO series của Ultralytics, được thiết kế để cải thiện hiệu suất phát hiện đối tượng thời gian thực với các tính năng tiên tiến. Là một mô hình tiên tiến, hiện đại (state-of-the-art – SOTA), YOLOv8 kế thừa thành công từ các phiên bản trước, đồng thời giới thiệu những tính năng và cải tiến mới để nâng cao hiệu suất, tính linh hoạt và hiệu quả.
Khác với các phiên bản trước, YOLOv8 tích hợp cơ chế không dùng điểm neo (anchor-free) với phần đầu Ultralytics được tách riêng, sử dụng các kiến trúc backbone và neck tiên tiến, đồng thời tối ưu hóa sự cân bằng giữa độ chính xác và tốc độ, làm cho nó trở thành lựa chọn lý tưởng cho nhiều ứng dụng khác nhau. Do đó, YOLOv8 có thể hỗ trợ toàn bộ các tác vụ vision AI, bao gồm phát hiện đối tượng, phân đoạn, ước tính tư thế, theo dõi và phân loại. Tính đa dạng này cho phép người dùng tận dụng khả năng của YOLOv8 trong nhiều ứng dụng và lĩnh vực khác nhau.
YOLOv8 kế thừa nhiều ưu điểm từ các phiên bản trước đó, đồng thời mang lại một số cải tiến quan trọng:
- Tốc độ và hiệu suất: YOLOv8 được thiết kế để hoạt động nhanh hơn và hiệu quả hơn, ngay cả trên các thiết bị có tài nguyên hạn chế như điện thoại di động hay các thiết bị nhúng. Nhờ vào kiến trúc nhẹ, nó có thể đạt tốc độ xử lý lên tới hàng trăm khung hình mỗi giây.
- Độ chính xác cao hơn: YOLOv8 cải thiện khả năng phát hiện đối tượng nhỏ và các đối tượng phức tạp hơn, giúp tăng độ chính xác tổng thể.
- Dễ dàng tùy chỉnh: YOLOv8 cung cấp khả năng dễ dàng điều chỉnh mô hình và các siêu tham số (hyperparameters) để phù hợp với các bài toán thực tế khác nhau. Điều này làm cho mô hình trở nên linh hoạt trong các ứng dụng từ phát hiện đối tượng đến phân loại, phân đoạn (segmentation), và tracking đối tượng.
- Tích hợp tốt hơn với các framework mới: YOLOv8 tận dụng tốt các công nghệ và framework mới như PyTorch, đồng thời hỗ trợ việc huấn luyện và triển khai dễ dàng hơn qua các file ONNX, TensorRT.
4. Các phiên bản của mô hình YOLOv8
YOLOv8 cung cấp nhiều phiên bản mô hình khác nhau, phù hợp với từng yêu cầu cụ thể về tốc độ và độ chính xác. Ví dụ:
- YOLOv8n (Nano): Phiên bản nhỏ gọn, nhanh nhất, phù hợp cho các ứng dụng yêu cầu thời gian xử lý nhanh như trên các thiết bị nhúng.
- YOLOv8s (Small), YOLOv8m (Medium): Phiên bản cân bằng giữa tốc độ và độ chính xác, thích hợp cho các bài toán vừa và nhỏ.
- YOLOv8l (Large), YOLOv8x (Extra Large): Phiên bản lớn hơn, phù hợp cho các ứng dụng yêu cầu độ chính xác cao nhưng có thể chấp nhận tốc độ xử lý chậm hơn.
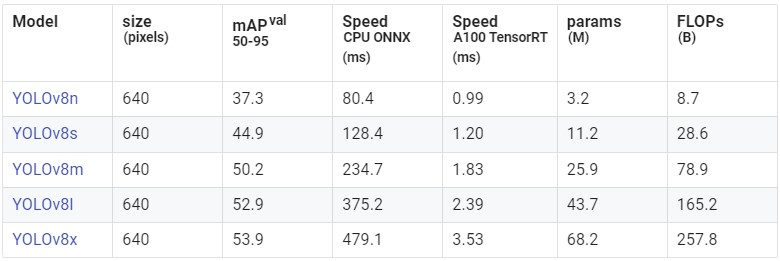
Dưới đây là bảng so sánh Performance của mô hình YOLOv8 Detection được train trên tập COCO, bao gồm 80 pre-trained classes.
5. Hướng dẫn sử dụng
- Các bạn cần cài đặt Python 3.8 x64 hoặc mới hơn.
- CUDA 11.8 và cuDNN 8.6.0
![]() Nên có GPU NVIDIA để tăng tốc xử lý, nếu xử lý bằng CPU tốc độ sẽ chậm
Nên có GPU NVIDIA để tăng tốc xử lý, nếu xử lý bằng CPU tốc độ sẽ chậm
Bạn cần cài đặt Pytorch, phiên bản chúng tôi đang sử dụng là 2.2.2
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu118
Tiếp theo các bạn cài đặt ultralytics
pip install ultralytics
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from ultralytics import YOLO # Load a COCO-pretrained YOLOv8n model model = YOLO("yolov8n.pt") # Display model information (optional) model.info() # Train the model on the COCO8 example dataset for 100 epochs results = model.train(data="coco8.yaml", epochs=100, imgsz=640) # Run inference with the YOLOv8n model on the 'bus.jpg' image results = model("path/to/bus.jpg") |
Chi tiết sẽ được trình bày trong bài viết sau.
6. Câu hỏi thường gặp
6.a Vì sao nên sử dụng YOLO?
YOLO là thuật toán hội tụ đủ các ưu điểm để tạo ra sản phẩm thương mại:
- Đủ chính xác, chạy nhanh và nhẹ
- Hỗ trợ nhiều ngôn ngữ lập trình, nhiều hệ điều hành và nhiều thiết bị khác nhau
- Giải quyết được nhiều bài toán khác nhau: object detection, segmentation, clasification và pose
- Mã nguồn mở và hoàn toàn miễn phí