VietOCR là thư viện nhận diện ký tự Việt Nam khá tốt. Tuy nhiên đối với một số bài toán đặc thù các bạn cần training lại để chính xác hơn.
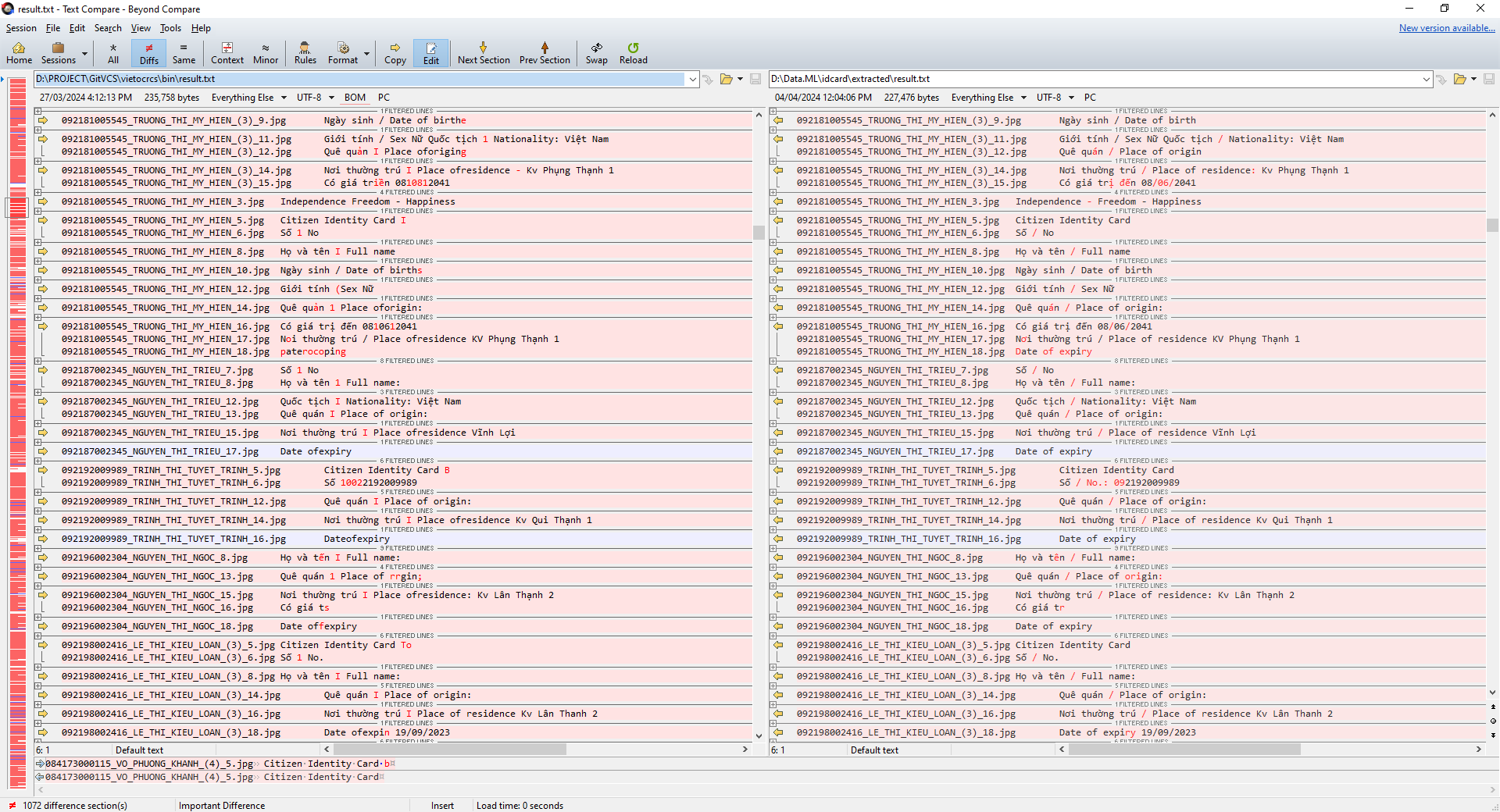
Để có thể so sánh độ chính xác của model gốc và model retrain bạn lưu kết quả nhận diện vào file text, sau đó so sánh với file kết quả sau khi training. Có thể thấy kết quả sau khi training lại có kết quả chính xác hơn (đã ẩn bớt 1 số dòng).
Bước 1: cài đặt các phần mềm cần thiết
Để training VietOCR các bạn cần có GPU NVIDIA, bên dưới là thông tin về cấu hình phần cứng và phần mềm cần thiết dùng để training.
- Python 3.8: tối thiểu là 3.8, không được thấp hơn
- CUDA 11.8 và cuDNN 8.9.5.30
- Windows 10 x64
- CPU: Intel i5 4590 3.3Ghz
- RAM: 16GB
- GPU: NVIDIA RTX 3060 12GB VRAM
- Visual Studio Code: để chạy Jupyter Notebook cho tiện
- VietOCR-cpp: script training nằm trong folder tools/training
Cài đặt Pytorch CUDA
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu118
Bước 2: crop vùng ảnh chứa text
Các bạn có thể dùng Paddle OCR để extract text. Và để training hiệu quả các bạn Warp perspective ảnh trước khi save.
Ảnh cắt ra từ CCCD

Warp perspective cho thẳng thớm

Do bộ data CCCD nhạy cảm nên các bạn tự chuẩn bị bộ data.
Bước 3: đánh nhãn hình ảnh
Bạn sử dụng tool VietOCR labeling để đánh nhãn.
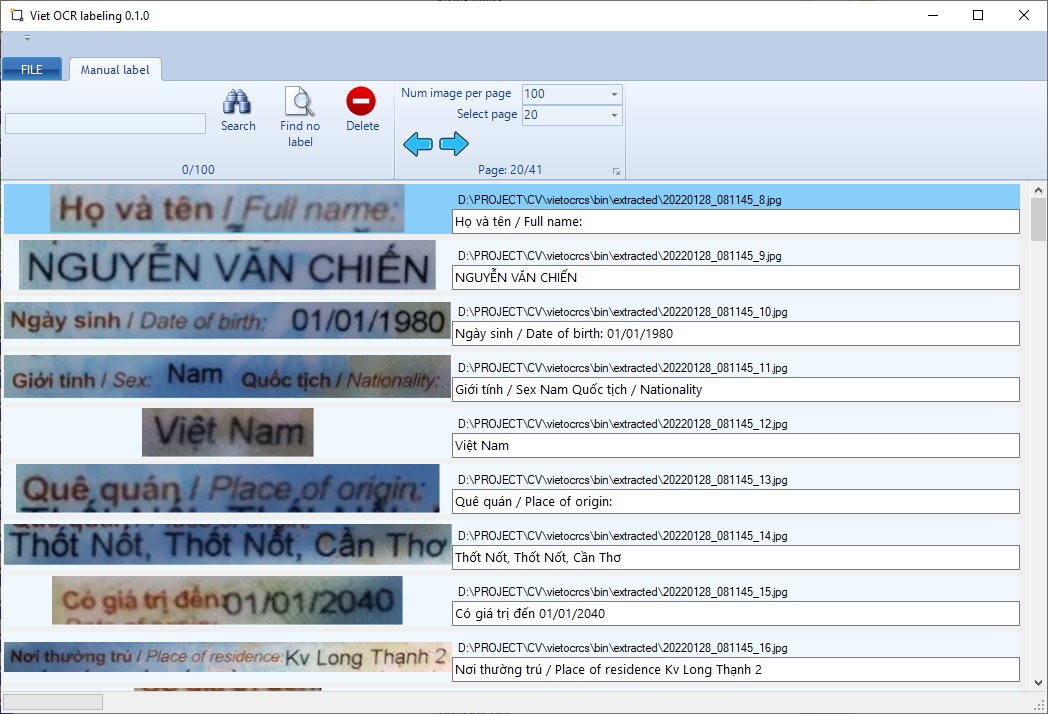
Sau khi đánh nhãn xong trong folder chứa hình ảnh sẽ có file label.txt chứa annotation của bộ ảnh.
Bước 4: training
Chạy Visual Studio Code và open folder vietocr-cpp/tools/training trong
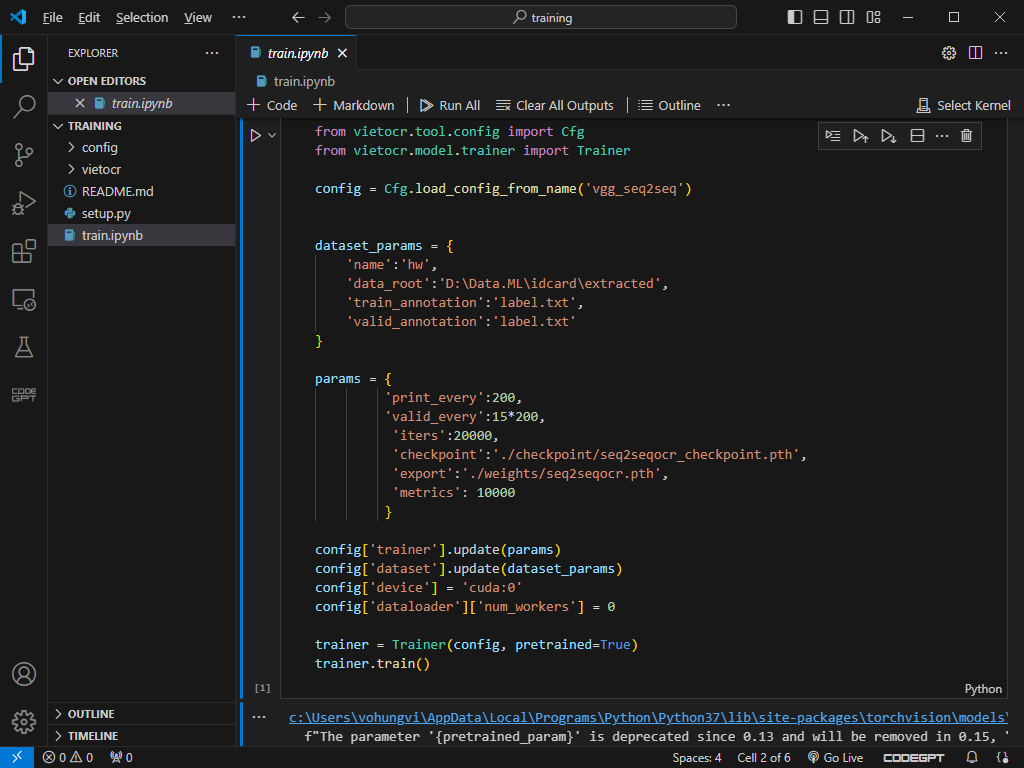
Sau đó các bạn cần sửa tham số training trong file train.ipynb như sau:
|
1 2 3 4 5 6 |
dataset_params = { 'name':'hw', 'data_root':'D:\Data.ML\idcard\extracted', 'train_annotation':'label.txt', 'valid_annotation':'label.txt' } |
Trong đó:
- name: tên của bộ dataset, có thể đặt tùy ý
- data_root: folder chứa ảnh
- train_annotation: file txt đã đánh nhãn
- valid_annotation: file txt đã đánh nhãn, các bạn nên tách file label thành 2 file train & valid riêng biệt
Ấn start để bắt đầu training, chương trình sẽ training trong khoảng 4 giờ, kết quả là file weights/seq2seqocr.pth
Để inference các bạn dùng đoạn code Python sau:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import matplotlib.pyplot as plt from PIL import Image from vietocr.tool.predictor import Predictor from vietocr.tool.config import Cfg config = Cfg.load_config_from_name('vgg_transformer') config['weights'] = './seq2seqocr.pth' config['cnn']['pretrained']=False config['device'] = 'cpu' detector = Predictor(config) |
Bước 5: Convert sang ONNX (optional)
Bước này dùng để convert file pth sang file onnx để VietOCR-cpp có thể chạy được. Nếu các bạn chỉ sử dụng Python thì bỏ qua bước này.
- Copy file seq2seqocr.pth vào folder tools/convert2onnx/weight.
- Vào folder tools/convert2onnx/ sửa file Converter.py
- Thay đường dẫn tương ứng của weight_path, mặc định là ./weight/seq2seqocr.pth
- Chạy file Converter.py
Kết quả được file cnn.onnx, decoder.onnx và encoder.onnx nằm chung folder weight.
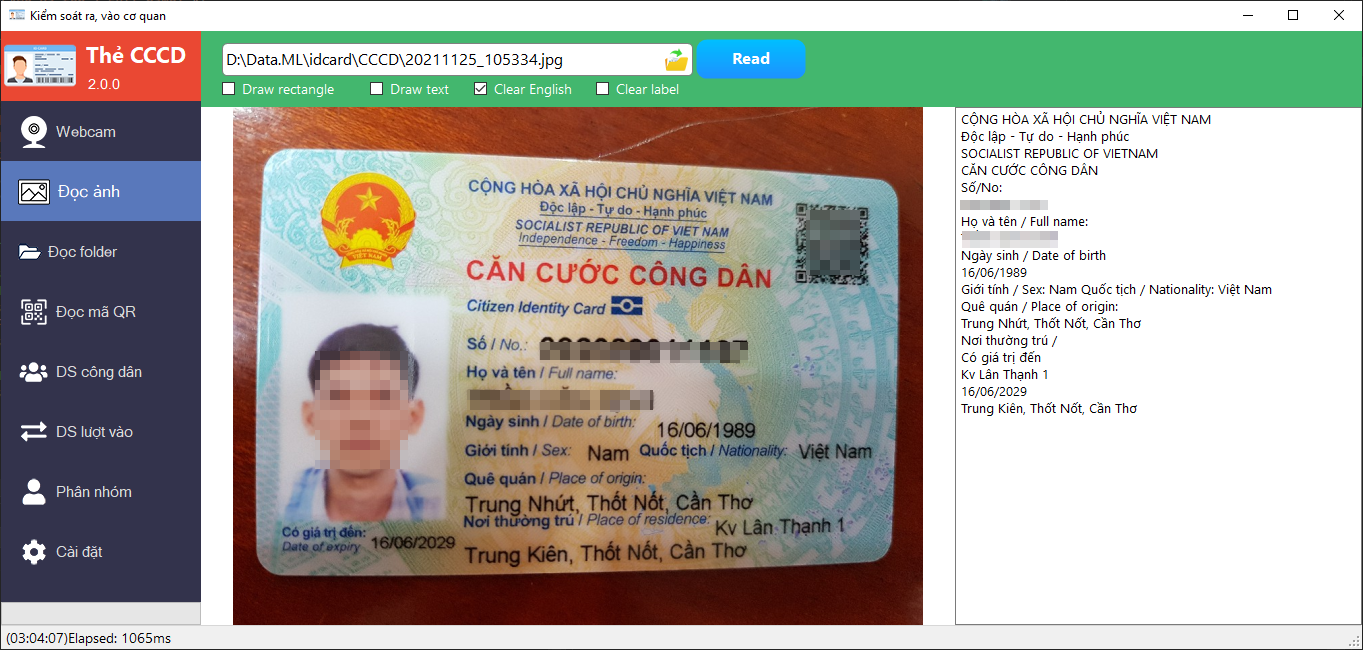
Kết quả ứng dụng: https://viscomsolution.com/phan-mem-doc-thong-tin-can-cuoc-cong-dan/
Về data thì em không xin, nhưng em có thể xin model đã được training lại không ạ?
Đây là sản phẩm thương mại của cty nên mình không share được rồi