FAISS (Facebook AI Similarity Search) là một thư viện mã nguồn mở được phát triển bởi đội ngũ nghiên cứu AI của Facebook (Facebook AI Research). Đây là một công cụ mạnh mẽ dành cho việc tìm kiếm độ tương đồng (similarity search) và phân cụm (clustering) các vector trong không gian đa chiều. Trong bài hướng dẫn này, chúng ta sẽ tìm hiểu về công dụng của FAISS, các giải thuật chính mà nó sử dụng, độ chính xác, và so sánh với các thư viện khác.
Nhờ những giải thuật mạnh mẽ & hiệu quả như vậy mà sản phẩm của Facebook đáp ứng được nhu cầu sử dụng của hàng tỷ người.
Link GitHub: https://github.com/facebookresearch/faiss
Mục lục
- Công dụng của FAISS
- Các Giải thuật trong FAISS
- Độ chính xác của FAISS
- So sánh với các thư viện khác
- Ví dụ đơn giản sử dụng FAISS
- Giải thích thêm về L2 distance
- Kết Luận
1. Công dụng của FAISS
FAISS được thiết kế để giải quyết bài toán tìm kiếm các vector gần giống nhất trong một tập dữ liệu lớn, thường được ứng dụng trong các lĩnh vực như:
- Tìm kiếm hình ảnh (Image Retrieval): So sánh đặc trưng của bức ảnh đầu vào (query) với tập dữ liệu để trả về các hình ảnh tương tự.
- Hệ thống gợi ý (Recommendation Systems): Tìm kiếm các mục (items) tương tự dựa trên biểu diễn vector của chúng.
- Xử lý ngôn ngữ tự nhiên (NLP): Tìm kiếm ngữ nghĩa gần giống trong không gian từ vựng hoặc câu.
- Phân cụm dữ liệu (Clustering): Nhóm các vector tương tự lại với nhau để phân tích hoặc trực quan hóa.
FAISS đặc biệt hữu ích khi làm việc với tập dữ liệu có kích thước lớn (hàng triệu đến hàng tỷ vector) nhờ khả năng tối ưu hóa tốc độ tìm kiếm mà vẫn duy trì được độ chính xác cao. Nó hỗ trợ cả CPU và GPU, giúp tăng tốc xử lý trên các hệ thống phần cứng hiện đại.
2. Các Giải thuật trong FAISS
FAISS cung cấp nhiều giải thuật khác nhau, cho phép người dùng cân bằng giữa tốc độ và độ chính xác tùy theo nhu cầu. Dưới đây là một số giải thuật tiêu biểu:
2.1. Exact Search (Tìm kiếm chính xác)
- Mô tả: Đây là phương pháp tìm kiếm đơn giản nhất, sử dụng khoảng cách Euclid (L2) hoặc tích vô hướng (inner product) để tính toán độ tương đồng giữa các vector.
- Ưu điểm: Đảm bảo kết quả chính xác 100%.
- Nhược điểm: Tốc độ chậm khi tập dữ liệu lớn, vì nó phải tính toán khoảng cách cho từng vector trong tập dữ liệu.
2.2. Approximate Nearest Neighbors (ANN – Tìm kiếm gần đúng)
- Inverted File Index (IVF): Chia tập dữ liệu thành các cụm nhỏ hơn bằng cách sử dụng phân cụm k-means. Khi tìm kiếm, chỉ các cụm gần với vector truy vấn mới được kiểm tra.
- Product Quantization (PQ): Nén dữ liệu bằng cách chia vector thành các đoạn nhỏ và mã hóa chúng, giảm bộ nhớ cần thiết và tăng tốc độ tìm kiếm.
- HNSW (Hierarchical Navigable Small World): Sử dụng đồ thị phân cấp để tìm kiếm nhanh các neighbor gần nhất, rất hiệu quả với độ chính xác cao.
2.3. Hỗ trợ CUDA
FAISS hỗ trợ các giải thuật được tối ưu cho GPU, như IVF và PQ, giúp tăng tốc độ tìm kiếm lên hàng chục lần so với CPU trên các tập dữ liệu lớn.
Đặc điểm chung
Các giải thuật ANN chấp nhận đánh đổi một phần độ chính xác để tăng tốc độ, nhưng FAISS cho phép tinh chỉnh để đạt được hiệu suất mong muốn.
Người dùng có thể kết hợp các phương pháp (ví dụ: IVF + PQ) để tối ưu hóa cả tốc độ lẫn độ chính xác.
3. Độ chính xác của FAISS
Độ chính xác của FAISS phụ thuộc vào giải thuật được chọn và các tham số cấu hình:
- Exact Search: Đạt độ chính xác 100%, nhưng không khả thi với dữ liệu lớn do yêu cầu tính toán cao.
- ANN (IVF, PQ, HNSW): Độ chính xác thường dao động từ 80-95%, tùy thuộc vào:
- Số lượng cụm (clusters) trong IVF: Số cụm càng lớn, độ chính xác càng cao nhưng tốc độ giảm.
- Mức nén trong PQ: Nén càng mạnh, độ chính xác càng giảm nhưng tiết kiệm bộ nhớ và tăng tốc độ.
- Số lượng liên kết trong HNSW: Tăng số liên kết cải thiện độ chính xác nhưng làm chậm quá trình tìm kiếm.
FAISS cung cấp công cụ để đo lường độ chính xác (recall), giúp người dùng đánh giá tỷ lệ các kết quả đúng được trả về so với kết quả lý tưởng. Ví dụ, với HNSW, độ chính xác có thể đạt gần 99% trong khi vẫn nhanh hơn đáng kể so với Exact Search.
4. So sánh với các thư viện khác
FAISS không phải là thư viện duy nhất trong lĩnh vực tìm kiếm tương đồng. Dưới đây là so sánh với một số đối thủ phổ biến:
4.1. Annoy (Approximate Nearest Neighbors Oh Yeah)
- Điểm mạnh: Đơn giản, dễ sử dụng, phù hợp với tập dữ liệu nhỏ và trung bình.
- Điểm yếu: Không hỗ trợ GPU, tốc độ và khả năng mở rộng kém hơn FAISS khi làm việc với dữ liệu lớn.
- So sánh: FAISS vượt trội về hiệu suất và khả năng tùy chỉnh.
4.2. HNSWlib
- Điểm mạnh: Tối ưu hóa cho giải thuật HNSW, rất nhanh và chính xác với dữ liệu vừa và nhỏ.
- Điểm yếu: Không đa dạng giải thuật như FAISS, không hỗ trợ nén dữ liệu (PQ).
- So sánh: FAISS linh hoạt hơn nhờ tích hợp nhiều giải thuật và hỗ trợ GPU.
4.3. NMSLIB (Non-Metric Space Library)
- Điểm mạnh: Hỗ trợ không gian không metric (non-metric spaces), phù hợp với một số ứng dụng đặc biệt.
- Điểm yếu: Ít tối ưu cho dữ liệu lớn và không có hỗ trợ GPU mạnh như FAISS.
- So sánh: FAISS vượt trội về tốc độ và khả năng xử lý dữ liệu lớn.
4.4. Elasticsearch với Vector Search
- Điểm mạnh: Tích hợp tốt với hệ thống tìm kiếm văn bản, dễ triển khai trong ứng dụng thực tế.
- Điểm yếu: Hiệu suất tìm kiếm vector thấp hơn FAISS, đặc biệt với dữ liệu lớn.
- So sánh: FAISS nhanh hơn và tối ưu hơn cho các tác vụ chuyên sâu về vector.
Kết luận
FAISS nổi bật nhờ sự kết hợp giữa tốc độ, độ chính xác và khả năng mở rộng. Nó phù hợp cho các ứng dụng đòi hỏi xử lý dữ liệu lớn và phức tạp, trong khi các thư viện khác như Annoy hay HNSWlib có thể tốt hơn cho các dự án nhỏ hoặc yêu cầu đơn giản hơn.
5. Ví dụ đơn giản sử dụng FAISS
Dưới đây là một đoạn code Python minh họa cách cài đặt và sử dụng FAISS để tìm kiếm vector gần nhất:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import numpy as np import faiss # Tạo dữ liệu giả lập d = 64 # chiều của vector nb = 10000 # số lượng vector trong tập dữ liệu nq = 10 # số lượng vector truy vấn np.random.seed(123) xb = np.random.random((nb, d)).astype('float32') # tập dữ liệu xq = np.random.random((nq, d)).astype('float32') # truy vấn # Tạo index với Exact Search (L2 distance) index = faiss.IndexFlatL2(d) index.add(xb) # Thêm dữ liệu vào index # Tìm kiếm 5 neighbor gần nhất k = 5 distances, indices = index.search(xq, k) print("Khoảng cách:", distances) print("Chỉ số:", indices) |
6. Giải thích thêm về L2 distance
L2 distance là thuật toán mạnh, hiệu quả, ứng dụng tốt trong sản phẩm, vì vậy cần giải thích rõ hơn cách sử dụng.
L2 distance, còn được gọi là khoảng cách Euclid (Euclidean distance), là một cách để đo “độ xa” giữa hai điểm trong không gian. Hãy tưởng tượng bạn đang đứng ở một điểm trên bản đồ và muốn biết khoảng cách thẳng đến một điểm khác – đó chính là ý tưởng của L2 distance.
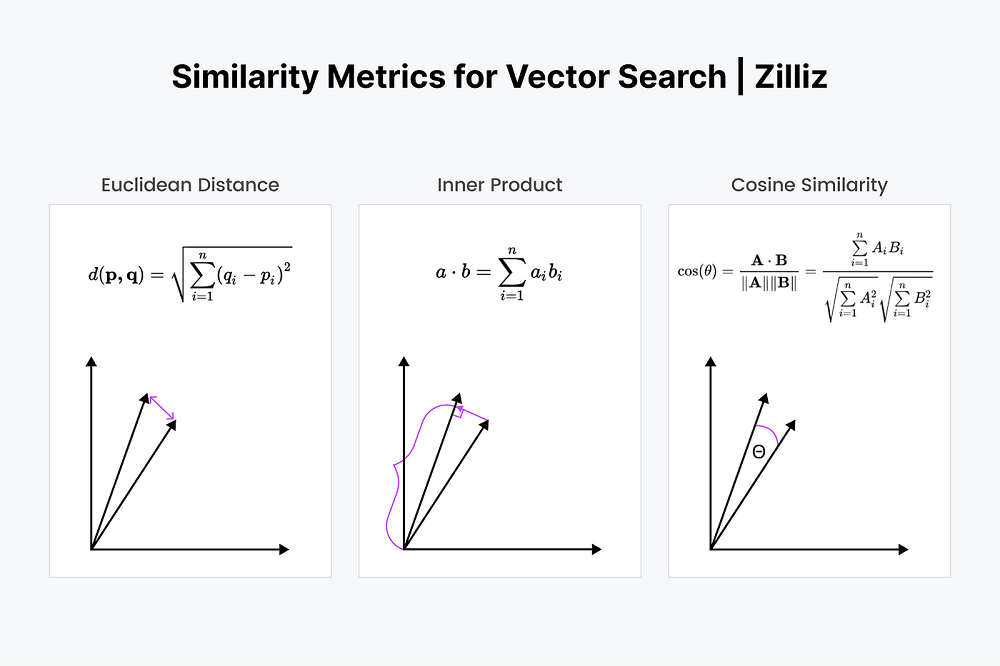
Trong toán học và lập trình, nó thường được dùng để so sánh hai vector (một tập hợp các số đại diện cho một điểm trong không gian nhiều chiều). L2 distance tính toán khoảng cách “đường chim bay” giữa hai vector này.
Tại sao L2 Distance quan trọng trong FAISS?
Trong FAISS, L2 distance được dùng để đo độ tương đồng giữa hai vector. Khi bạn tìm kiếm “vector gần nhất” (nearest neighbor), FAISS sẽ so sánh vector truy vấn (query) với các vector trong tập dữ liệu và chọn ra những vector có L2 distance nhỏ nhất – nghĩa là chúng “gần” nhau nhất trong không gian.
Ưu điểm của L2 Distance
- Trực quan: Nó giống như cách chúng ta đo khoảng cách trong thế giới thực (ví dụ, từ nhà bạn đến trường học).
- Nhạy với độ lớn: Nếu một chiều của vector thay đổi nhiều, L2 distance sẽ tăng đáng kể vì mọi chênh lệch đều được bình phương.
- Dễ tính toán: Công thức đơn giản và được tối ưu trong các thư viện như FAISS.
7. Kết Luận
FAISS là một công cụ mạnh mẽ và linh hoạt cho các bài toán tìm kiếm tương đồng và phân cụm vector. Với nhiều giải thuật từ chính xác tuyệt đối (Exact Search) đến gần đúng nhanh chóng (ANN), FAISS đáp ứng tốt nhu cầu đa dạng của người dùng.
So với các thư viện khác, FAISS vượt trội về hiệu suất, khả năng mở rộng và hỗ trợ phần cứng hiện đại. Nếu bạn đang làm việc với dữ liệu lớn và cần một giải pháp tối ưu, FAISS chắc chắn là lựa chọn đáng cân nhắc.