Bạn đang dùng YOLOv8 (hoặc các model khác tương tự) nhưng CPU & GPU chưa chạy hết 100% công suất. Bài viết này hướng dẫn bạn cách lập trình đa luồng để có thể khai thác tối đa sức mạnh phần cứng.
Lập trình đa luồng (multithread) chỉ có tác dụng với bài toán xử lý nhiều ảnh trong folder, xử lý video,… còn nếu chỉ đọc 1 ảnh thì không cần thiết multithread.
Nếu CPU/GPU chỉ chạy khoảng 30-40% thì mới nên lập trình multithread, còn CPU/GPU đã chạy 80-90% trở lên thì multithread không có tác dụng đáng kể. Lúc đó tốn công lập trình và làm cho phần mềm phức tạp không đáng có.
Hầu như các ngôn ngữ lập trình hiện đại đều hỗ trợ lập trình đa luồng. Trong xử lý và nhận diện hình ảnh thì C++ và Python đều có sẵn thư viện hỗ trợ, các bạn không cần cài đặt gì thêm.
Các nguyên tắc khi lập trình đa luồng – multithread
Các nguyên tắc bên dưới xảy ra khi sử dụng bài toán Deep Learning và cũng ứng dụng tương tự cho các bài toán khác.
- Một model chỉ detect 1 ảnh, nếu model đang detect mà gọi hàm detect ảnh khác sẽ gây ra crash
- Số lượng thread tùy thuộc vào sức mạnh phần cứng, đầu tiên bạn cứ để 2 thread. 2 thread mà vẫn chưa full load thì tăng lên đến khi gần full load thì dừng (90% là đẹp)
- Nếu chạy full load mà vẫn chưa đáp ứng nhu cầu realtime thì nâng cấp phần cứng hoặc thay model nhẹ hơn
- Để cho phần cứng bền bỉ bạn nên để máy chạy dưới 50% công suất. Chạy ở mức độ load cao hoặc full load sẽ làm thiết bị mau hư hỏng
- Hàm print() có thể làm giảm performance của chương trình
Bài viết này sử dụng video https://www.youtube.com/watch?v=9_nwSrwpKYA
Bước 1: Detect ảnh bằng YOLO v8 đơn luồng (single thread)
Đoạn code bên dưới dùng để detect ảnh bằng YOLO v8, đầu tiên là load model vào 1 biến, sau đó detect video như bình thường, không sử dụng thread
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
from ultralytics import YOLO import cv2 import torch if torch.cuda.is_available(): torch.cuda.set_device(0) print("using CUDA") else: print("using CPU") model = YOLO("yolov8n.pt") cap = cv2.VideoCapture("laocai.mp4") def Predict(frame): results = model(frame, device=0) return results while cap.isOpened(): ret, frame = cap.read() if not ret: break results = Predict(frame) print(results) cap.release() |
Bước 2: lập trình đa luồng (multithread)
Đầu tiên bạn tạo 1 mảng models, mảng này chứa các model YOLOv8. Số lượng phần từ trong mảng tương đương số luồng bạn muốn chạy. Để xác định trạng thái của model các bạn 1 mảng bool thứ 2 để kiểm tra trạng thái mode đang detect hay không.
|
1 2 3 |
models = [] availableIdxes = [] MAX_THREADS = 2 |
Bạn sẽ cần 1 function để điều tiết mọi thứ. Function này sẽ trả về index của model đang rảnh, nếu không có model nào rảnh thì trả về -1. Tuy nhiên nếu tất cả đều đang bận và số model đang nhỏ hơn số lượng bạn muốn thì load thêm model.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
models = [] availableIdxes = [] MAX_THREADS = 2 def GetAvailableIdx(): for i, model in enumerate(models): if(availableIdxes[i]): return i if(len(models) < MAX_THREADS): model = YOLO("yolov8n.pt") models.append(model) availableIdxes.append(True) return len(models) - 1 return -1 |
Bây giờ trong vòng lặp các bạn cần tìm model nào đang rảnh bằng cách tìm trong mảng availableIdxes, nếu không rảnh thì chờ 0.01 giây (10 milisecond). Nếu model nào đó rảnh thì đánh dấu là bận để thread khác không sử dụng nữa, chỉ có thread hiện tại được sử dụng thôi.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
while cap.isOpened(): ret, frame = cap.read() if not ret: break availableIdx= GetAvailableIdx() while(available == -1): time.sleep(0.01) availableIdx = GetAvailableIdx() availableIdxes[availableIdx] = False t = threading.Thread(target=Predict, args=(frame, availableIdx)) t.start() |
Trong hàm Predict() bạn cần truyền vào frame và index của model hiện tại. Sau khi detect xong bạn đánh dấu model đã rảnh, sẵn sàng detect ảnh mới
|
1 2 3 4 5 |
def Predict(frame, availableIdx): results = models[availableIdx](frame, device=0) print(results) availableIdxes[available] = True return results |
Vậy là các bạn đã có thể khai thác tối đa phần cứng bằng cách cho chạy nhiều luồng.
Trong quá trình chạy bạn có thể thấy CPU chạy 100% mà CUDA chạy chưa full load (hoặc ngược lại) thì đó là hiện tượng nghẽn cổ chai. Bạn cần nâng cấp thiết bị yếu hơn để khai thác tối đa sức mạnh.
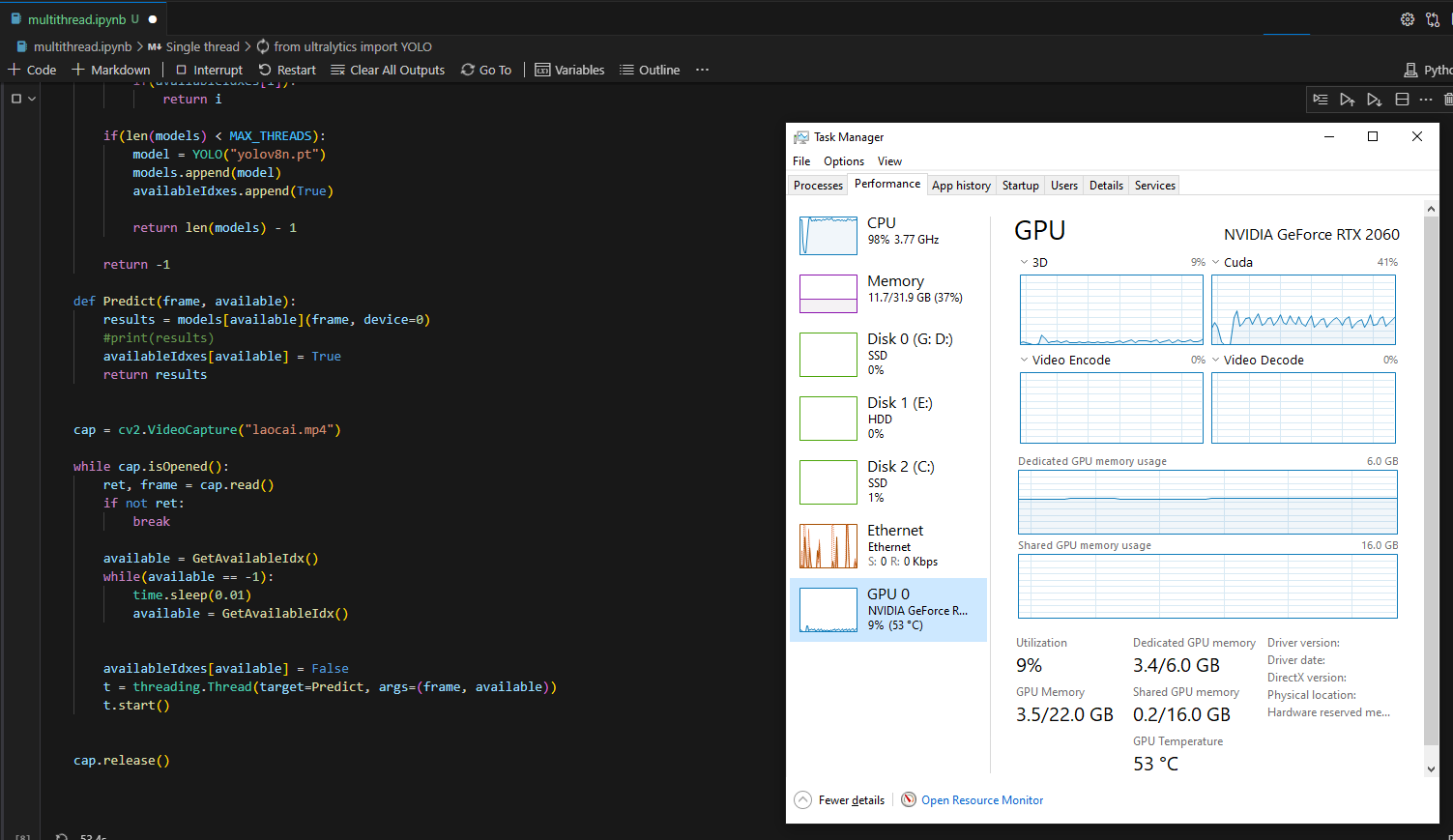
Full code multithread YOLOv8
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
from ultralytics import YOLO import cv2 import threading import time models = [] availableIdxes = [] MAX_THREADS = 2 def GetAvailableIdx(): for i, model in enumerate(models): if(availableIdxes[i]): return i if(len(models) < MAX_THREADS): model = YOLO("yolov8n.pt") models.append(model) availableIdxes.append(True) return len(models) - 1 return -1 def Predict(frame, available): results = models[available](frame, device=0) print(results) availableIdxes[available] = True return results cap = cv2.VideoCapture("laocai.mp4") while cap.isOpened(): ret, frame = cap.read() if not ret: break available = GetAvailableIdx() while(available == -1): time.sleep(0.01) available = GetAvailableIdx() availableIdxes[available] = False t = threading.Thread(target=Predict, args=(frame, available)) t.start() cap.release() |